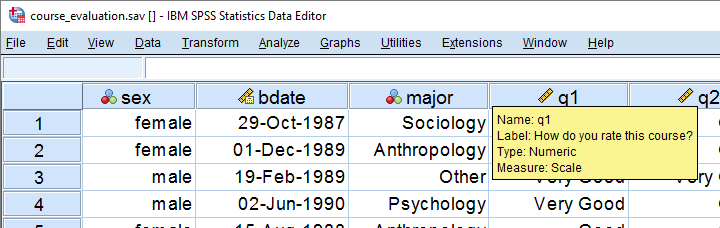
A teacher held a course evaluation. The data in SPSS format are in course-evaluation.sav, part of which is shown below. Students from different majors participated and now the education director wants separate Excel files for each major. A super easy way for creating these is by using SPSS with Python. We'll walk you through.
1. Save SPSS Data as Excel File
We'll first just create syntax for saving all data as a single Excel file from SPSS’ menu. We'll navigate to
![]() and fill it out as below.
and fill it out as below.
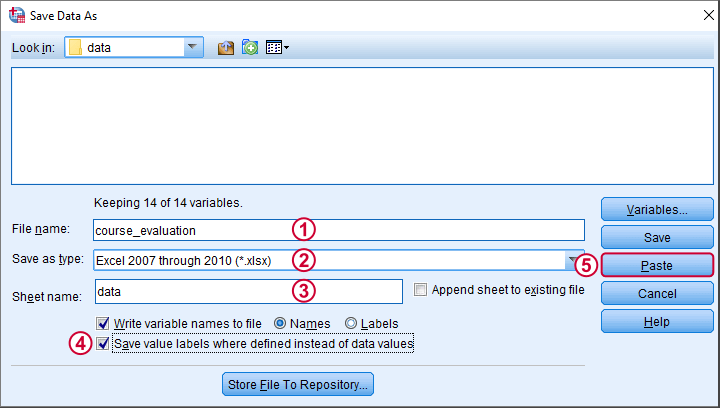
This results in the syntax below.
SAVE TRANSLATE OUTFILE='D:\data\course_evaluation.xlsx'
/TYPE=XLS
/VERSION=12
/FIELDNAMES
/CELLS=LABELS
/REPLACE.
2. Selecting Which Cases to Save
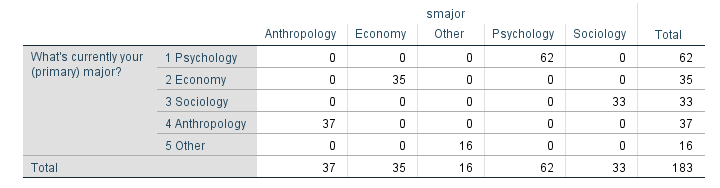
Our first syntax saves all cases -that is, all majors- as one Excel file. A neat way to save only a subset of cases -one major at the time- is using SELECT IF and preceding it with TEMPORARY. Like so, we could copy-paste-edit our syntax for each major. We'll have Python do just that for us. But first we'll convert our study majors into an SPSS string variable with the syntax below.
string smajor (a20).
compute smajor = valuelabel(major).
crosstabs major by smajor.
Result
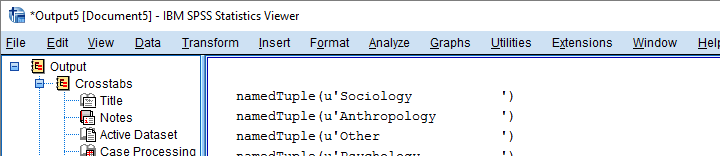
3. Look Up Data Values with Spssdata
A Python SPSS module developed for looking up data values is spssdata. Doing so is super easy as shown by the syntax below. The main pitfall here is using the correct casing, which is spssdata.Spssdata.
begin program python3.
import spssdata
for case in spssdata.Spssdata('smajor'):
print(case)
end program.
Result
4. Cleaning Up Our Majors
As we see, Python returns a tuple for each case holding a student’s major as a Python string. We'll first extract this first (and only) element from each tuple by succeeding it with [0] as shown below.
Note that each major is right padded with spaces up to a total length of 20. This is because its variable format
in SPSS is A20. In Python, we'll remove these spaces with strip().
begin program python3.
import spssdata
for case in spssdata.Spssdata('smajor'):
print(case[0].strip())
end program.
5. Unduplicating Our Majors
At this point, Python retrieves all majors in a good, clean way. But since we only need the create one Excel file for each distinct major, we need to unduplicate these. We'll first create an empty Python list object. We'll then add each major to this list only if it's not yet in there.
begin program python3.
import spssdata
majors = []
for case in spssdata.Spssdata('smajor'):
major = case[0].strip()
if major not in majors:
majors.append(major)
print(majors)
end program.
Result

6. Create and Inspect SPSS Syntax
Our Python list of distinct majors looks great! If you're very paranoid, run
FREQUENCIES SMAJOR.
in SPSS to confirm that these really are the majors in our data. Now that we have this in place, we won't recreate it but proceed with the second step.
The syntax below first creates an empty Python string. Next, we'll loop over distinct majors and concatenate some SPSS syntax to it that we created earlier from the menu. In this syntax, we added %s which we use for a Python text replacement. The result is a substantial block of SPSS syntax which we'll first inspect.
begin program python3.
spssSyntax = ''
for major in majors:
spssSyntax += '''
TEMPORARY.
SELECT IF (smajor = '%s').
SAVE TRANSLATE OUTFILE='D:\data\course_evaluation_%s.xlsx'
/TYPE=XLS
/VERSION=12
/FIELDNAMES
/CELLS=LABELS
/REPLACE.
'''%(major,major.lower())
print(spssSyntax)
end program.
Result
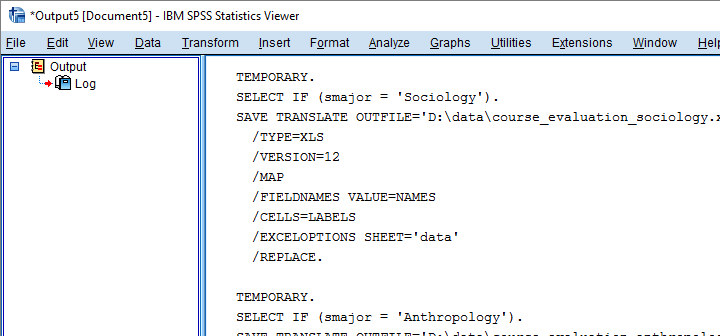
7. Run Our Syntax
Since our syntax looks fine, we'll run it with spss.Submit. In order to use this, we still need to import the spss module because we hadn't done so thus far.
begin program python3.
import spss
spss.Submit(spssSyntax)
end program.
Result
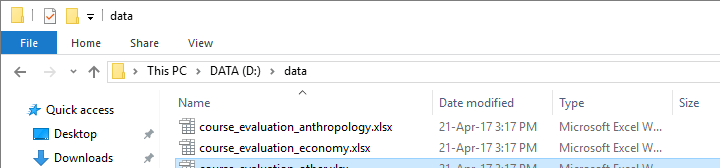
Final Notes
In short, Python can very easily look up data values with spssdata.Spssdata(). Restrict it to a single variable by specifying its name in the parentheses. Leaving the parentheses empty looks up the data values of all variables.
Once we have our data values in Python, we can insert them into SPSS syntax or do a ton of other stuff with them.
Thanks for reading!
THIS TUTORIAL HAS 34 COMMENTS:
By Raina on August 29th, 2014
Hello! This syntax does not exactly work for an spss *.sav file that I am trying to use it on. I have modified the code minimally:
begin program python.
import spss,spssdata
allSchools = set([school[0].strip() for school in spssdata.Spssdata('AGENCYNAME').fetchall()])
for school in allSchools:
spss.Submit('''
temporary.
select if AGENCYNAME = '%(school)s'.
save translate outfile = 'Data_%(school)s.xlsx'
/type = xlsx
/version = 12
/fieldnames.'''%locals())
end program.
What should result is 21 different *.xlsx files for each of the 21 unique names for my grouping variable (AGENCYNAME) in my original file, but only 13 *.xlsx files are actually created. The original file only has 567
By Raina on August 29th, 2014
(Continued from previous comment...)The original file only has 567 cases, so it should not be a problem there.
Furthermore when I copy the syntax above as an example to create the new data file for universities, the correct number of *.xlsx files (4) are created for Yale, Harvard, Princeton, and Stanford.
Help!
By Ruben Geert van den Berg on August 29th, 2014
Are you sure all 21 unique values are actually present in the data? Do you see all of them when running FREQUENCIES?
Do you get any errors or warnings when you switch off PRINTBACK and MPRINT?
Try to print allSchools in line 5 and then END PROGRAM and see what you get.
Please let me know whether that helps.
By Raina on August 29th, 2014
Thanks for your reply! Yes, I am 100% positive all 21 unique values on my grouping variable are there... A frequency report lists the frequencies for all 21 values.
I even changed my grouping variable to be 'University' so I wouldn't have to change anything in your code above. Still the same result-- only the same 13 *.xlsx files as before. When I run your code with the renamed variable, I get error messages in the SPSS Output window it looks like this:
cd 'c:/temp2'.
begin program.
import spss,spssdata
allSchools = set([school[0].strip() for school in spssdata.Spssdata('University').fetchall()])
for school in allSchools:
spss.Submit('''
temporary.
select if University = '%(school)s'.
save translate outfile = 'Data_%(school)s.xls'
/type = xls
/version = 8
/fieldnames.'''%locals())
end program.
>Warning # 208 in column 53. Text: ' '
>A text string is not correctly enclosed in quotation marks on the command
>line. Literals may not be continued across command lines without the use of
>the continuation symbol '+'.
>Error # 4830 in column 38. Text: S
>There is extraneous text following the logical expression on a SELECT IF
>command.
>Execution of this command stops.
>Warning # 208 in column 64. Text: ' '
>A text string is not correctly enclosed in quotation marks on the command
>line. Literals may not be continued across command lines without the use of
>the continuation symbol '+'.
>Error # 9013 in column 45. Text: S
>Unrecognized subcommand. The recognized subcommands are: APPEND, CELLS,
>COMPRESSED, CONNECT, DROP, EDITION, ENCODING, ENCRYPTED, FIELDNAMES, KEEP,
>MAP, MISSING, OUTFILE, PLATFORM, RENAME, REPLACE, SQL, TABLE, TEXTOPTIONS,
>TYPE, UNCOMPRESSED, UNENCRYPTED, UNSELECTED, VALFILE, and VERSION.
>Execution of this command stops.
Traceback (most recent call last):
File "", line 11, in
File "C:\Python27\lib\site-packages\spss210\spss\spss.py", line 1525, in Submit
raise SpssError,error
spss.errMsg.SpssError: [errLevel 3] Serious error.
By Raina on August 29th, 2014
(Continued from previous comment...) I am new to python (but experienced in SPSS syntax), and am not familiar with how to switch off PRINTBACK or MPRINT. I read your other page "Introduction to Python - Four Tips'. Do you have any suggestions of where I could read about these commands and how to execute them within the context of this code?
Lastly, after I ran the first code, I ran this code all by itself:
begin program python.
import spss
firstvar=spss.GetVariableName(0)
print allSchools
end program.
The result was interesting... In the SPSS Output window, it listed all 21 unique values of the grouping variable, but it listed the 13 values that the *.xlsx files were made for first, and the 8 values that there were no *.xlsx files for last:
set([u'PINAL COUNTY', u'GREENLEE COUNTY', u'MARANA HEALTH CENTER', u'MOHAVE COUNTY', u'MARIPOSA', u'COCOPAH TRIBE', u'YUMA COUNTY', u'GILA COUNTY', u'MARICOPA COUNTY', u'YAVAPAI COUNTY', u'NAVAJO COUNTY', u'DESERT SENITA', u'GRAHAM COUNTY', u"ST ELIZA
BETH'S HEALTH CENTER", u'PIMA COUNTY', u'APACHE COUNTY', u'MOUNTAIN PARK', u'COCONINO COUNTY', u'COCHISE COUNTY', u'ADELANTE HEALTHCARE', u'EL RIO'])