6. Inconvenient Distributions
(Overview and data file are found here)
Let's first state this clearly: we don't exclude variables simply because their distributions are not to our liking. What we mean by “inconvenient distributions” are variables that don't really provide us with useful information.
This point is perhaps best explained by an example. Let's inspect q4. Since it's an ordinal variable, we'll create its frequency table and bar chart as usual:
frequencies q4/barchart.
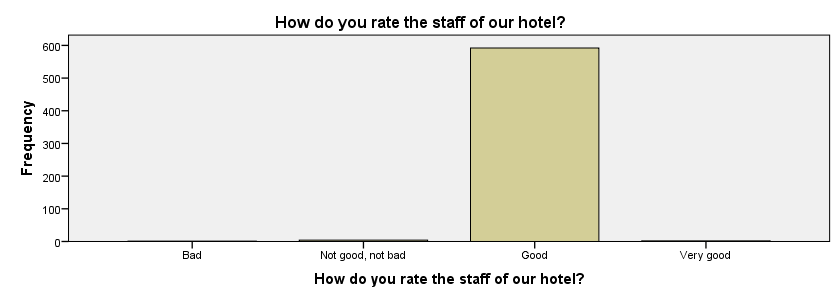
Right. Technically, there's nothing wrong with this variable. However, virtually all respondents have given the same answer. That is, this variable doesn't really provide us with any useful information. We might therefore remove it from the data or at least exclude it from analysis.
A different and more subtle example of inconvenient distributions are distributions looking very unusual. This may indicate that a variable doesn't really represent what it's supposed to.
7. Small Categories
(Overview and data file are found here)
Let's now inspect nation. This is a nominal variable so we'll run its frequency distribution and bar chart: frequencies nation/barchart.
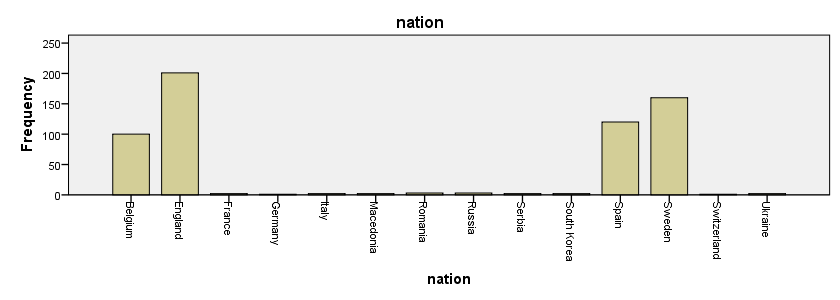
Again, there's nothing really wrong with this variable. However, many small categories being present is often undesirable. For example, let's inspect the average room prices per nationality by running means rprice by nation. The resulting table is overly large and many average prices are based on only 1, 2 or 3 respondents. Having many small categories also complicates some statistical procedures. In practice, we'll probably merge these small categories into one and label it “Other nationality”.
8. Undesirable Coding
(Overview and data file are found here)
An example of undesirable coding is seen when inspecting q5. This is an ordinal variable so we'll inspect its frequency table and barchart by running frequencies q5/barchart.
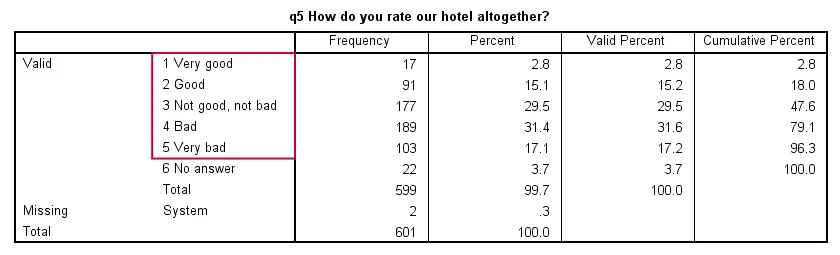
At first glance, this variable looks good. We do need to specify 6 as a user missing value and there's some system missing values too but altogether there's not that many missing values. The bar chart looks good too: no weird distribution or small categories.
However, note that the lowest value (1) reflects the most positive attitude (“Very good”). There's nothing really wrong with that but for ordinal variables we usually want higher values to reflect higher amounts or more positive attitudes. This is especially important if we want to compare variables with different coding schemes.