When we start analyzing a data file, we first inspect our data for a number of common problems. For instance, we want to be sure that variables have the right formats, don't contain any weird values and have plausible distributions. This tutorial proposes which steps should be taken and in which order.
This tutorial shows how to get a quick case count and variable count. Next, we'll inspect whether our case identifier variable does not contain duplicate values.
A problem with some data files is that they contain string variables that should have been numeric. This tutorial shows how to detect and correct such variables.
Before you can do anything at all with your variables, you need to inspect them for user missing values. This tutorial shows how to find them quickly.
Scanning your variables for unusual distributions is easy and facilitates later steps in the analysis of your data. This tutorial shows how to do so quickly.
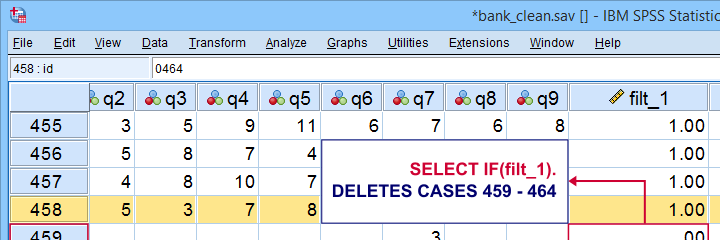
Before analyzing our data, we check whether they contain any bad cases. If these are present, we need to exclude them from our analyses.
THIS TUTORIAL HAS 5 COMMENTS:
By Alex on November 20th, 2019
Excellent
By KASAWANI @ KAZUWANI B IBRAHIM on February 14th, 2020
TQ AND GOOD JOB
By Erasto Manyua Nkomomola on February 14th, 2020
How can I get lectures notes
By Ruben Geert van den Berg on February 15th, 2020
Hi Erasto!
Sorry but you can't. We currently really only offer our online tutorials.
Kind regards,
SPSS tutorials
By MARK on April 15th, 2025
great work