In SPSS, IF computes a new or existing variable
for a selection of cases.
For analyzing a selection of cases, use FILTER or SELECT IF instead.
- Example 1 - Flag Cases Based on Date Function
- Example 2 - Replace Range of Values by Function
- Example 3 - Compute Variable Differently Based on Gender
- SPSS IF Versus DO IF
- SPSS IF Versus RECODE
Data File Used for Examples
All examples use bank.sav, a short survey of bank employees. Part of the data are shown below. For getting the most out of this tutorial, we recommend you download the file and try the examples for yourself.
Example 1 - Flag Cases Based on Date Function
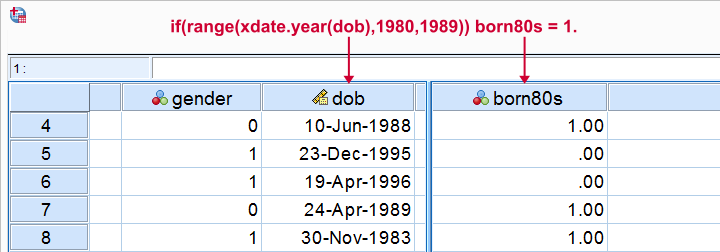
Let's flag all respondents born during the 80’s. The syntax below first computes our flag variable -born80s- as a column of zeroes. We then set it to one if the year -extracted from the date of birth- is in the RANGE 1980 through 1989.
compute born80s = 0.
*Set value to 1 if respondent born between 1980 and 1989.
if(range(xdate.year(dob),1980,1989)) born80s = 1.
execute.
*Optionally: add value labels.
add value labels born80s 0 'Not born during 80s' 1 'Born during 80s'.
Result
Example 2 - Replace Range of Values by Function
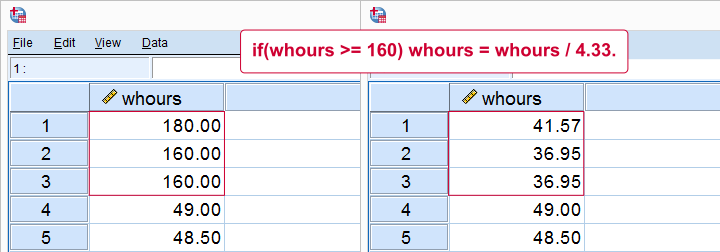
Next, if we'd run a histogram on weekly working hours -whours- we'd see values of 160 hours and over. However, weeks only hold (24 * 7 =) 168 hours. Even Kim Jong Un wouldn't claim he works 160 hours per week!
We assume these respondents filled out their monthly -rather than weekly- working hours. On average, months hold (52 / 12 =) 4.33 weeks. So we'll divide weekly hours by 4.33 but only for cases scoring 160 or over.
sort cases by whours (d).
*Divide 160 or more hours by 4.33 (average weeks per month).
if(whours >= 160) whours = whours / 4.33.
execute.
Result
Note
We could have done this correction with RECODE as well: RECODE whours (160 = 36.95)(180 = 41.57). Note, however, that RECODE becomes tedious insofar as we must correct more distinct values. It works reasonably for this variable but IF works great for all variables.
Example 3 - Compute Variable Differently Based on Gender
We'll now flag cases who work fulltime. However, “fulltime” means 40 hours for male employees and 36 hours for female employees. So we need to use different formulas based on gender. The IF command below does just that.
compute fulltime = 0.
*Set fulltime to 1 if whours >= 36 for females or whours >= 40 for males.
if(gender = 0 & whours >= 36) fulltime = 1.
if(gender = 1 & whours >= 40) fulltime = 1.
*Optionally, add value labels.
add value labels fulltime 0 'Not working fulltime' 1 'Working fulltime'.
*Quick check.
means whours by gender by fulltime
/cells min max mean stddev.
Result
Our syntax ends with a MEANS table showing minima, maxima, means and standard deviations per gender per group. This table -shown below- is a nice way to check the results.
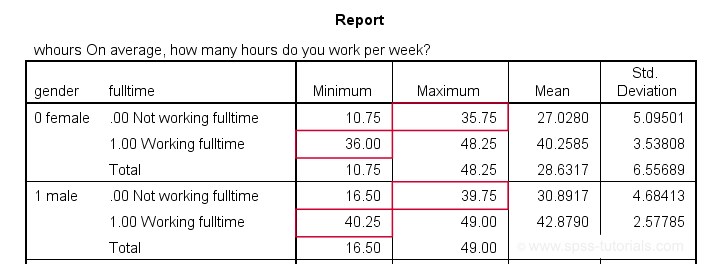
The maximum for females not working fulltime is below 36. The minimum for females working fulltime is 36. And so on.
SPSS IF Versus DO IF
Some SPSS users may be familiar with DO IF. The main differences between DO IF and IF are that
- IF is a single line command while DO IF requires at least 3 lines: DO IF, some transformation(s) and END IF.
- IF is a conditional COMPUTE command whereas DO IF can affect other transformations -such as RECODE or COUNT- as well.
- If cases meet more than 1 condition, the first condition prevails when using DO IF - ELSE IF. If you use multiple IF commands instead, the last condition met by each case takes effect. The syntax below sketches this idea.
DO IF - ELSE IF Versus Multiple IF Commands
do if(condition_1).
result_1.
else if(condition_2). /*excludes cases meeting condition_1.
result_2.
end if.
*IF: respondents meeting both conditions get result_2.
if(condition_1) result_1.
if(condition_2) result_2. /*includes cases meeting condition_1.
SPSS IF Versus RECODE
In many cases, RECODE is an easier alternative for IF. However, RECODE has more limitations too.
First off, RECODE only replaces (ranges of) constants -such as 0, 99 or system missing values- by other constants. So something like
recode overall (sysmis = q1).
is not possible -q1 is a variable, not a constant- but
if(sysmis(overall)) overall = q1.
works fine. You can't RECODE a function -mean, sum or whatever- into anything nor recode anything into a function. You'll need IF for doing so.
Second, RECODE can only set values based on a single variable. This is the reason why
you can't recode 2 variables into one
but you can use an IF condition involving multiple variables:
if(gender = 0 & whours >= 36) fulltime = 1.
is perfectly possible.
You can get around this limitation by combining RECODE with DO IF, however. Like so, our last example shows a different route to flag fulltime working males and females using different criteria.
Example 4 - Compute Variable Differently Based on Gender II
recode whours (40 thru hi = 1)(else = 0) into fulltime2.
*Apply different recode for female respondents.
do if(gender = 0).
recode whours (36 thru hi = 1)(else = 0) into fulltime2.
end if.
*Optionally, add value labels.
add value labels fulltime2 0 'Not working fulltime' 1 'Working fulltime'.
*Quick check.
means whours by gender by fulltime2
/cells min max mean stddev.
Final Notes
This tutorial presented a brief discussion of the IF command with a couple of examples. I hope you found them helpful. If I missed anything essential, please throw me a comment below.
Thanks for reading!
THIS TUTORIAL HAS 61 COMMENTS:
By Ruben Geert van den Berg on December 5th, 2016
Hi Laura! The right way to do this, is set 0 as a user missing value
with something like
missing values v1 to v4 (0).Then use COMPUTE with the MEAN function:compute somemean = mean(v1 to v4).Try and run the syntax below step by step. It creates a handful of test cases. Means are computed only over nonzero values as you can easily see. Hope that helps!
data list free/id.
begin data
1 2 3 4 5 6 7 8 9 10
end data.
*2. Create 4 test variables holding values from 0 through 3.
set seed 1.
do repeat #new = v1 to v4.
compute #new = rv.binom(3,0.5).
end repeat.
execute.
*3. Set zero as missing value.
missing values v1 to v4 (0).
*4. Compute mean over only nonzero values.
compute mymean = mean(v1 to v4).
execute.
By ALBERTO ZUCCHI on December 14th, 2016
Hello again, Ruben!
I have an unusual problem (for what is my knowledge, at least), and I'm sure you can give me substantial help.
I have a sequence of data, concerning patients undergoing rehabilitation procedures, like this:
ID Var1 Data1 Data2 .... Flag
where ID is the unique ID for each patient. I have 1 to n possible IDs as cases (real facts, 1 to 21 IDs).
Var1 is defining the hospital kind of take-in-charge (ie, non rehab or rehab).
Data1 is day of hospital take-in charge, and data2 is day of hospital discharge.
I need to know, for each ID's rehab take-in charge,, if there is an antecedent non-reahab take in charge comprised in a time span of 7 days, and so flag it with a dummy variable (flag).
By example:
ID Var1 data1 data2
1 non rehab 02/15/2016 02/20/2016
1 rehab 02/23/2016 02/26/2016
1 rehab 04/05/2016 04/10/2016
In this case, the second record of patient n. 1 must be flagged as, by example, 1 (ie there are less than 7 days between the discharge date of first antecedent non rehab take-in charge of a rehab take-in charge).
Of course, first record of ID1 will have a flag equal to 0, and so the 3rd take-in charge (being anteceded by another rehab take-in charge).
I've tried to use restructurate command, to perform on single Ids put on single row all operations, but problem is that I have IDs that have till 21 take in charges,so the new dataset is multiplying variables in a too wide excess. Any suggestion, Ruben?
Many thanks!
Alberto Zucchi
By Ruben Geert van den Berg on December 16th, 2016
Hi Alberto! This sounds like a serious challenge. Could you perhaps send me a sample of these data by email? I'm off today but perhaps I can try and write the desired syntax on Saturday/Sunday.
By Toria Vi on January 23rd, 2017
Hi Ruben, I'm a phd student & I find your website very informative, easy to read and succinct. Here's my question:
I need to create a dichotomous variable yes/no based on whether cases meet a particular cut-off score on a subscaleae. Now, that is simple enough with a recode into a different variable. The problem I'm having is the cut-off score varies based on the cases' gender/age. I.E: if the case is a boy aged =12, or if case is girl =14 etc. All recoded into the same variable. Thank you.
By Ruben Geert van den Berg on January 23rd, 2017
Hi Toria!
You can't recode 2 variables into one. Your easiest option may be IF with multipe conditions as in
compute outcomevariable = 0.if(gender = 1 and score >= 12) outcomevariable = 1.
if(gender = 2 and score >= 14) outcomevariable = 1.
execute.
If one condition occurs in many such statements, you can write cleaner (thus better) syntax with DO IF as in
do if (gender = 0).recode score (0 thru 11 = 0)(12 thru 25 = 1) into outcomevariable.
*possibly more statements here for (gender = 0)....
else if (gender = 1).
recode score (0 thru 14 = 0)(15 thru 25 = 1) into outcomevariable.
*possibly more statements here for (gender = 1)....
end if.
Hope that helps!