In SPSS, LAG is a function that returns the value of a previous case. It's mostly used on data with multiple rows of data per respondent. Here it comes in handy for calculating cumulative sums or counts.
 SPSS Lag Function
SPSS Lag Function
SPSS LAG - Basic Example 1
The most basic way to use LAG is COMPUTE V1 = LAG(V2). This simply computes a (possibly new) variable V1 holding the value of the previous case on V2. This is illustrated by the first screenshot. It's the result of running the syntax below. Since the first case doesn't have a previous case, it has a system missing value on the new variable.
SPSS LAG Syntax Example 1
data list free / id.
begin data
1 2 2 3 3 3 4 4 4 4
end data.
*2. Find id value of previous case.
compute previous_id = lag(id).
exe.
SPSS Lag - Creating a Counter
A great way to illustrate how LAG works is to create a counter variable. For each id value we'll create a variable that indicates its nth row of data. We'll start by identifying the first record of each id by using an IF command as shown in the syntax below. How it works is illustrated by the screenshot.
if $casenum = 1 or id ne lag(id) counter = 1.
exe.
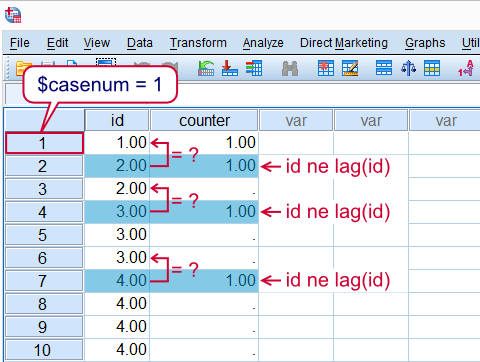 Identify first row for each id value
Identify first row for each id value
Next we'll finish our counter. What's important to understand here is that cases are processed sequentially from top to bottom when SPSS executes data transformations. That is, SPSS will start at $casenum = 1 and work its way down case by case. So a value created by LAG during this process may be used by the next case. The screenshot below illustrates three of the steps that occur while SPSS processes the syntax below.Since these steps usually require milliseconds to complete you don't actually see them occurring in normal situations.
if sysmis(counter) counter = lag(counter) + 1.
exe.
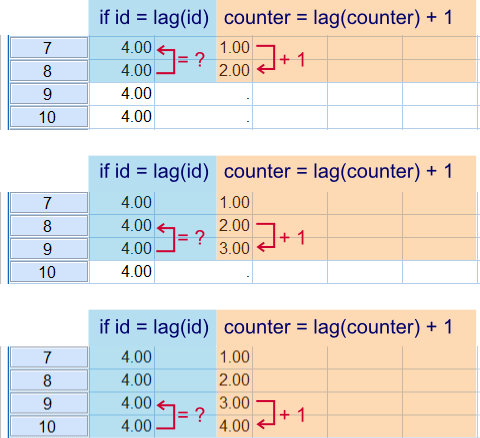 SPSS processes cases sequentially from top to bottom
SPSS processes cases sequentially from top to bottom
SPSS Long Data Format
 SPSS Long Data Format. Note how each customer can have one or more records.
SPSS Long Data Format. Note how each customer can have one or more records.
We'll continue with real world examples that gradually increase in level. Say we have data holding orders as records as in the figure above. Note that each customer can have one or several rows of data. This format is often referred to as a long data format.The opposite of this, with each customer's data on a single row, is called a wide data format. Relevant questions regarding these data may be
- How often do customers place an order? Or alternatively, how many days pass between orders by one customer?
- How many orders does the average customer place?
- How much money do customers spend?
We'll walk through these questions using the LAG function for answering them.
SPSS LAG Example - Days Between Orders
Running the syntax below will create the data from the previous screenshot and find the days between orders by one customer. Note that the records must first be sorted in a meaningful way. Next, if customer_id = lag(customer_id) checks whether each record is not the first record for a given customer. Only for these records days_between_orders will be calculated.
SPSS LAG Syntax Example 2
data list free / order_id (f2.0) order_date(edate10) customer_id invoice_amount (2f3.0).
begin data
1 26.09.2011 8 100 2 30.10.2011 8 100 3 28.12.2011 3 100 4 21.01.2012 12 150 5 26.01.2012 3 110
6 31.01.2012 7 140 7 16.02.2012 12 190 8 22.02.2012 12 30 9 23.02.2012 3 150 10 04.04.2012 12 50
end data.
*2. Sort records by customer_id and then order_date.
sort cases customer_id order_date.
*3. Compute days between orders by single customer.
if customer_id = lag(customer_id) days_between_orders = datediff(order_date,lag(order_date),'days').
exe.
SPSS LAG Example - Cumulative Orders per Customer
Now we'll create a cumulative order count per customer. We'll first set this new variable to 1 for each customer's first record. This is selected by if $casenum = 1 or lag(customer_id) ne customer_id. Next, we'll add 1 to it for each consecutive record if it belongs to the same customer. This condition is implied by if customer_id = lag(customer_id) Note that we make use of the fact that SUM(SYSTEM MISSING,X) = X. We can't use the + operator here because SYSTEM MISSING + X = SYSTEM MISSING.
SPSS LAG Syntax Example 3
if $casenum = 1 or lag(customer_id) ne customer_id cumulative_orders = 1.
exe.
*2. For each consecutive record, add 1 to cumulative_orders.
if customer_id = lag(customer_id) cumulative_orders = sum(lag(cumulative_orders),1).
exe.
SPSS LAG Example - Cumulative Expenditure
Finally we'll create the cumulative expenditure. This works quite similarly to the previous example. Instead of adding 1 to each consecutive record, we now add invoice_amount.
SPSS LAG Syntax Example 4
if $casenum = 1 or lag(customer_id) ne customer_id cumulative_amount = invoice_amount.
exe.
*2. Cumulative amount for second through nth records.
if customer_id = lag(customer_id) cumulative_amount = sum(invoice_amount,lag(cumulative_amount)).
exe.
 Original variables and those created by using LAG
Original variables and those created by using LAG
Notes
- As a rule of thumb, always run
EXECUTEimmediately after commands usingLAG. This is one of the very few cases where you really need to runEXECUTEor a procedure.The reason for this is rather technical but for those who wonder:LAGis always carried out after all other transformations. This means that the order in which commands are executed may deviate from the order in which they're specified. So if a variable affected byLAGis used in a subsequent command, the latter is likely to use the ‘wrong’ values becauseLAGhasn't taken place yet. - In order to get the value of the nth previous case, use
LAG(...,n). Note thatnmust be a positive integer. That is, you can't useLAG(v1,-1)for getting the value from the next instead of the previous case.
Getting Values from Next Cases
LAGcan't readily access values from next rather than previous cases. If you do need the value of a next case, one option is to reverse the order of the cases and useLAGanyway.- You can also get values from next cases with
CREATEorSHIFT VALUES. Note that these are procedures (and not functions). This means you can't use them in anIFcommand for evaluating conditions like we did in most of the examples discussed in this tutorial.
Additional Examples
Shortly after writing this tutorial we received some more challenging questions that are solved by using mainly LAG and IF statements. We'll walk through them below.
SPSS Lag - Identifying Sessions
“We held an experiment in which respondents were presented with random pictures. Each picture may or may not occur repeatedly. Subsequent presentations of a single picture constitute a session. How can we add these sessions to our data?”
The syntax below focuses on explaining how things work, step by step. It's not the fastest option for answering the question.For one way to shorten it, see Compute A = B = C.
SPSS LAG Syntax Example 5
data list free / sequence id picture.
begin data.
1 1 1 2 1 4 3 1 3 4 1 4 5 1 4 6 1 4 7 1 1 8 1 1 9 1 3 10 1 3 1 2 3 2 2 3 3 2 3 4 2 4 5 2 2 6 2 4 7 2
1 8 2 2 9 2 3 10 2 1 1 3 1 2 3 3 3 3 3 4 3 4 5 3 4 6 3 2 7 3 1 8 3 4 9 3 3 10 3 3
end data.
variable labels id 'Respondent id'.
*.2 Session = 1 for every respondent's first row of data.
if $casenum eq 1 or id ne lag(id) session = 1.
exe.
*3. Detect switches (different picture for same respondent).
if $casenum gt 1 and id eq lag(id) and picture ne lag(picture) switch = 1.
exe.
*4. Increase session with 1 for every switch.
if $casenum ne 1 and id eq lag(id) session = sum(lag(session),switch).
exe.
*5. Optionally, delete "switch".
delete variables switch.
SPSS Lag - Count Votes in Households
“We collected data on different people in households. One of our variables, vote is the political party each respondent would vote for when asked. We'd like to estimate the political heterogeneity of households by counting the number of different values on vote. How can we do this?”
Note the use of AGGREGATE in step 6. As with the previous example, this syntax could be shortened.
SPSS LAG Syntax Example 6
data list free / household_member household vote.
begin data
1 1 4 1 2 3 2 2 3 3 2 1 4 2 1 5 2 4 1 3 3 2 3 4 1 4 1 2 4 4 1 5 2 2 5 2 3 5 3 4 5 4 5 5 1
end data.
*2. Sort by household, then vote.
sort cases by household vote.
*3. For first member of household, counter = 1.
if $casenum = 1 or household ne lag(household) counter = 1.
exe.
*4. Identify switches (vote changes within household).
if $casenum ne 1 and household = lag(household) and vote ne lag(vote) switch = 1.
exe.
*5. Increase counter by 1 for every switch.
if $casenum ne 1 and household = lag(household) counter = sum(lag(counter),switch).
exe.
*6. Different votes in household = max(counter).
aggregate outfile = * mode addvariables
/break household
/different_votes_in_household = max(counter).
*7. Optionally delete temp helper variables.
delete variables counter switch.
THIS TUTORIAL HAS 54 COMMENTS:
By Ronald on August 8th, 2014
Hi, I am trying to do session identification for clickstream data. I want to increase the count when a certain amount of time has elapsed between clicks (e.g. 3 minutes). The difficulty is updating the count to know what number it is should be on.
By Ruben Geert van den Berg on August 9th, 2014
First, keep in mind that a proper SPSS time variable is nothing else than a number of seconds displayed as (HH:MM) or (HH:MM:SS). I'm not sure what the exact structure of your data is but perhaps you can construct cumulative time per person, divide that by 180 (seconds, = 3 minutes) and truncate the result in order to count sessions. For a single respondent example, have a look at this syntax. Let me know whether that helps.
By S. Daniel on August 31st, 2014
Hi Ruben, thank you for these pages, they have been an enormous help while doing my thesis. I would have a simple (hope so) question to add: in example 2 you calculate dates between orders. Using the same logic, how can I calculate difference of numeric (scale) variables (i.e. purchase amounts) between orders? I tried with replacing datediff to "diff" and wiping off the 'days' from the end, but it keeps saying error.
By Ruben Geert van den Berg on September 1st, 2014
Just use the
-operator: if your numeric variable is calledv1, try something likeif customer_id = lag(customer_id) new_variable = v1 - lag(v1).By S. Daniel on September 1st, 2014
Thank you so much! You are my statistics hero!