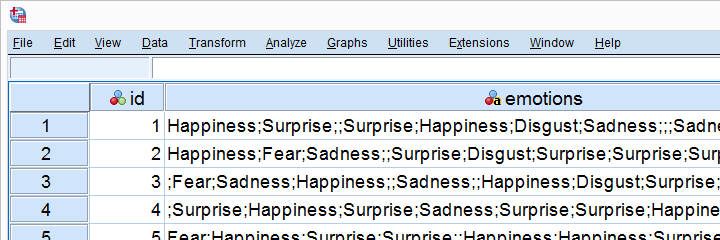
After importing some data into SPSS, some answers ended up in a single string variable. The data are in splitstrings.sav, part of which is shown below. Excel has a nice “text to columns” function to split it but SPSS hasn't... So you think you can syntax? Then let's go and split this string into the original answers.
Step 1 - New String Variables
First off, I'll make two guesses:
- I guess my long string variable surely doesn't hold more than 30 answers;
- I guess none of these answers is longer than 25 characters.Or -when in SPSS Unicode mode- 25 bytes. Which often corresponds to 25 characters.
If my guesses are right, then 30 new string variables -each of length 25- should be able to hold all answers. But no worries: if my guesses are wrong, I'll find out after performing the string splitting exercise.
Step 2 - Split String Syntax
We'll basically split our string by combining VECTOR and LOOP in a somewhat unusual way. Those who find it difficult may want to take a look at this long version with comments.
string emo_1 to emo_30 (a25).
*Split string: each ";" indicates a new answer.
string #char(a1).
compute #index = 1.
vector emo = emo_1 to emo_30.
loop #pos = 1 to char.length(emotions).
compute #char = char.substr(emotions,#pos,1).
if(#char <> ";") emo(#index) = concat(rtrim(emo(#index)),#char).
if(#char = ";") #index = #index + 1.
end loop.
execute.
Result
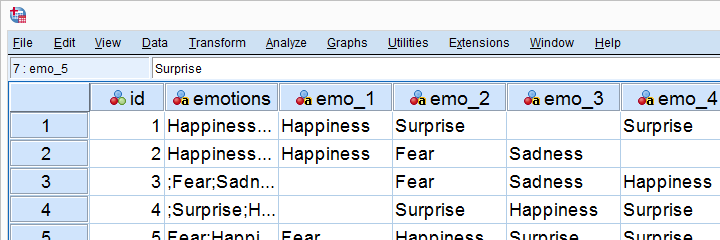
Step 3 - Check Results
For each of our 30 new emo_ variables, we'll now create a numeric variable which holds the lengths of the string values. If my guesses about the number of answers and their lengths were right, then
- None of these check variables should hold a length over 24. If they do, then some original answers may have been truncated.
- The last check variable(s) should hold only zeroes. This means that the last new string variables are empty, implying that 30 new variables were indeed enough. If this isn't the case, I may have created insufficient new variables.
Syntax for Checking Results
do repeat #old = emo_1 to emo_30 / #new = len_1 to len_30.
compute #new = char.length(#old).
end repeat.
*Variables having max <= 24 have not been truncated because our new strings all have length 25.
descriptives len_1 to len_30.
Result
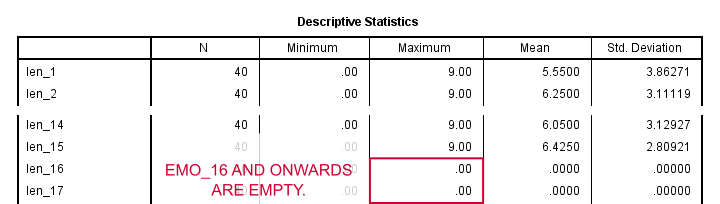
Only the first 15 new variables contain non zeroes. Retrospectively, just 15 (not 30) new string variables would have been enough. Hey, but doesn't everything always look better retrospectively?
Second, none of our new string variables holds any value longer than 9 characters/bytes. No values were truncated. These two checks confirm that our operation has fully succeeded. Let's now clean things up a bit.
Step 4 - Remove Redundant Variables
delete variables emo_16 to len_30.
*We'll now set all string variables to their minimum required length.
alter type all(a=amin).
Split Syntax with Comments
For those who found the splitting syntax a bit hard, I added some comments to the version below. Tip: copy-paste it into Notepad++ for easier reading.
string emo_1 to emo_30 (a25).
*As we'll loop over characters in original string, we'll pass each character into scratch variable #char for easier reference.
string #char(a1).
*Set up a vector. New string variables can now be referenced as emo(1), emo(2) and so on.
vector emo = emo_1 to emo_30.
*Set up counter #index for new string variables.
compute #index = 1.
*Now emo(#index) refers to emo_1. After adding 1 to #index, emo(#index) = emo_2. And so on.
*Loop over all characters in original string.
loop #pos = 1 to char.length(emotions).
*Pass character into #char.
compute #char = char.substr(emotions,#pos,1).
*If #char is not ";", add character to end of emo variable that's being constructed.
if(#char <> ";") emo(#index) = concat(rtrim(emo(#index)),#char).
*If char is ";", continue with next new string variable.
if(#char = ";") #index = #index + 1.
end loop.
execute.
Final Notes
I hope you enjoyed this fun little exercise as much as I did. But you probably didn't.
Thanks for reading!
THIS TUTORIAL HAS 17 COMMENTS:
By Jon Peck on May 1st, 2018
Well, this post demonstrates some useful SPSS syntax constructs, but for this type of problem, regular expressions are MUCH simpler and less error prone.
Here is a 1-command solution. It splits based on 1 or more ; characters and creates 30 new string variables of length 25.
spssinc trans result=emo_1 to emo_30 type=25
/formula "re.split(r';+', emotions)".
By Zulaikha on May 2nd, 2018
Thanks so much for the post. Really thank you! Great.
By Ruben Geert van den Berg on May 2nd, 2018
Hi Jon, thanks for your comment!
The point in this post was mainly to run a nice little (plain) syntax exercise and show how seemingly difficult tasks can sometimes be accomplished without Python.
For some sad reason, I still feel many SPSS users are still avoiding Python -I've been trying over and over again to demonstrate its usefulness but perhaps it's easier for us than for an average user...
Nevertheless, your suggestion is extremely useful! I'll add it to the post body. Nice that the re module is automatically imported when re.split() is called.
By J S on October 29th, 2018
How do I use this syntax and maintain spaces in my data? My string variables have spaces in them, but they are not printing in the new variables; rather the syntax causes SPSS to skip the spaces and only print the actual characters. For example, Doctor of Podiatry would become DoctorofPodiatry.
By Ruben Geert van den Berg on October 29th, 2018
Maintaining spaces can be somewhat tricky as SPSS tends to remove them from the ends of string values.
A simple and solid solution is replacing spaces by a different character that doesn't yet occur in the string values such as @. So try
compute mystring = replace(mystring,' ','@').After splitting the string, replace '@' by a space. You can speed this up if you nest the COMPUTE command in DO REPEAT.
Hope that helps!
SPSS tutorials