This tutorial walks through running nice tables and charts for investigating the association between categorical or dichotomous variables. If statistical assumptions are met, these may be followed up by a chi-square test.
As an example, we'll see whether sector_2010 and sector_2011 in freelancers.sav are associated in any way.
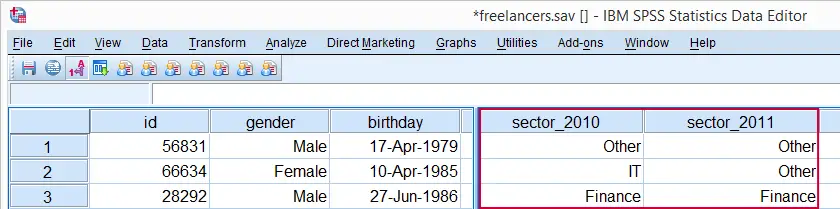
SPSS Quick Data Check
Before doing anything else, let's first just take a quick look at both variables separately. In the syntax below, we first ensure we'll see both values and value labels in our output tables (step 1). Next, we run a basic FREQUENCIES command.
set tnumbers both.
*2. Run frequencies.
frequencies sector_2010 sector_2011.
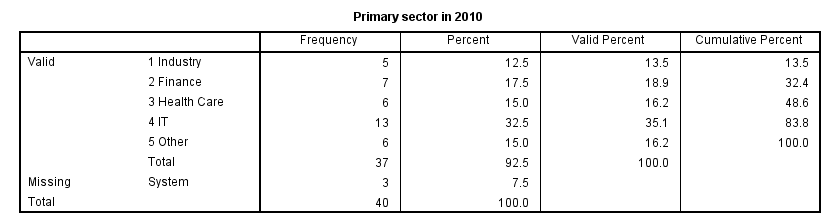
RECODE System Missing Values
Both variables contain values from 1 through 5 plus system missing values. Since both variables are nominal, we may include these system missings as just another category. This keeps the N nice and constant over analyses and results in cleaner tables.For nicer tables, you may remove “Valid” with a Python script and apply styling with an SPSS table template (.stt file). The syntax below shows how to do so with RECODE.
recode sector_2010 sector_2011 (sysmis = 6).
*2. Explain what formerly missing value means.
add value labels sector_2010 sector_2011 6 '(Unknown)'.
*3. Show only value labels in output.
set tnumbers labels.
*4. Run clean frequency tables.
frequencies sector_2010 sector_2011.
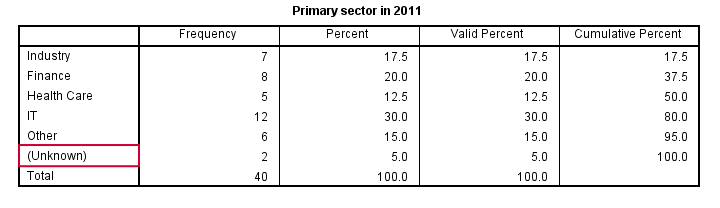
SPSS CROSSTABS for Both Variables
Thus far, we only had a look at both variables separately. In order to see how they're associated, we'll inspect their contingency table obtained from CROSSTABS. Displaying column percentages without frequencies is our preferred option here.
crosstabs sector_2011 by sector_2010
/cells column.
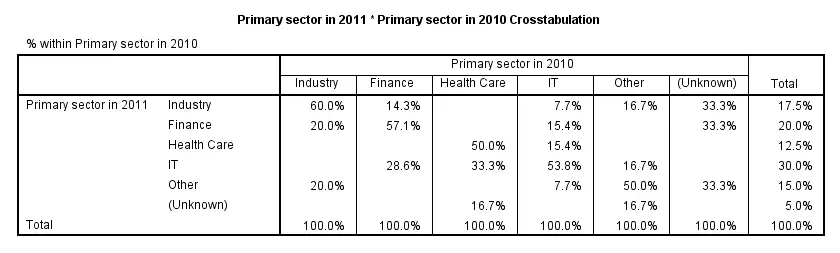
Conclusion: the variables are strongly related.Again, note that we're only describing the data at hand. We're not making any attempt to generalize these results to any larger population. Roughly, most people who worked in a sector in 2010 stayed in the same sector in 2011. For example, 60% of respondents who worked in industry in 2010 stayed in industry. Another 20% moved to finance and the final 20% moved to “other”.
SPSS Clustered Bar Chart Creation
We'll now visualize the contents of the previous table. An option here is a split bar chart but we'll go for a clustered bar chart instead. The screenshots below walk you through the process.
SPSS Clustered Bar Chart Syntax
GRAPH
/BAR(GROUPED)=COUNT BY sector_2011 BY sector_2010
/TITLE='Sector in 2010 by sector in 2011 (N = 40)'.
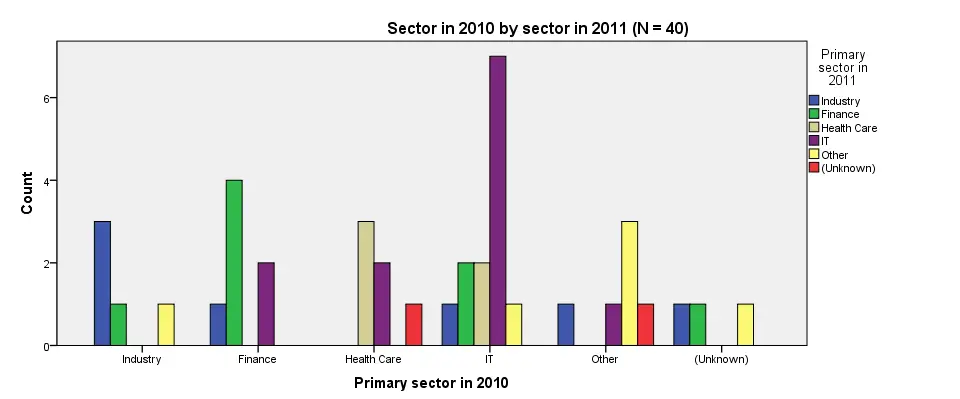
SPSS Clustered Bar Chart Styling
Although our chart is technically correct, it looks appalling. Its default color scheme basically just looks like a bad joke from the software developers. A fast way to prettify this and similar charts is building and applying an SPSS chart template (.sgt file). Our final result after doing so is shown in the last screenshot.
SPSS Clustered Bar Chart Example
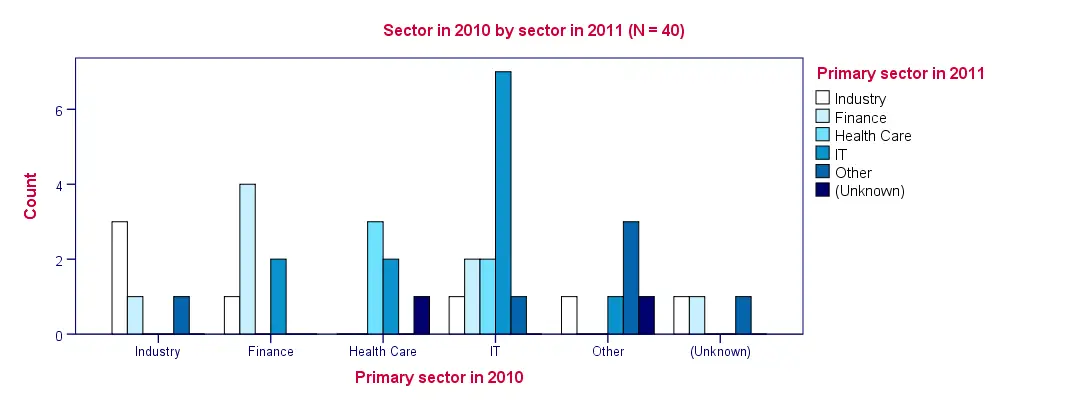
Conclusion: as with the contingency table, we don't see much of a clear pattern here except for people tending to stay in the same sector as the previous year.
THIS TUTORIAL HAS 14 COMMENTS:
By Wendy on March 8th, 2017
Yes, A, B etc are age groups (16-25, 26-35 etc). I also have body composition groups. For want of unPC titles they're skinny, normal, fat. So I'm trying to work out whether the ratios of skinny, normal, fat in the young age group is statistically different to that in the middle and old age groups, for example.
My data is just a sample (n=305) recruited at random from the general population.
Maybe I'm not thinking about this correctly..?
Thanks!
By Ruben Geert van den Berg on March 8th, 2017
I think you are thinking about it correctly. However, we usually want to limit the number of statistical tests we use. The more tests we run, the more opportunities we create for drawing erroneous conclusions.
So instead of comparing each age group on composition -3 separate tests, which you could do- we'll compare all 3 age groups in one chi-square independence test.
Each age group having similar percentages over body compositions comes down to finding out if age and composition are associated or independent. I tried to explain the basic idea here in Chi-Square Test - What Is It?.
The chi-square test shows if they are related. Next, a CROSSTAB with column or row percentages shows how they are related.
The aforementioned ARESID provide a sort of post hoc test which cells are statistically significantly under/overrepresented but I personally feel just 1 single chi-square test suffices -opinions do differ on this, though.
By Jayati Bhattacharjee on February 9th, 2018
Need to use SPSS and learn more about my research in behavioral sciences where the data is the comparison of science test of the different section of students.
By abi habtamu on April 28th, 2018
It is very nice to me
By Salem Udoh on August 14th, 2018
Very interesting . Could you recommend free SPSS download site for me. Thanks.