SPSS LAG Function – What and Why?
In SPSS, LAG is a function that returns the value of a previous case. It's mostly used on data with multiple rows of data per respondent. Here it comes in handy for calculating cumulative sums or counts.
 SPSS Lag Function
SPSS Lag Function
SPSS LAG - Basic Example 1
The most basic way to use LAG is COMPUTE V1 = LAG(V2). This simply computes a (possibly new) variable V1 holding the value of the previous case on V2. This is illustrated by the first screenshot. It's the result of running the syntax below. Since the first case doesn't have a previous case, it has a system missing value on the new variable.
SPSS LAG Syntax Example 1
data list free / id.
begin data
1 2 2 3 3 3 4 4 4 4
end data.
*2. Find id value of previous case.
compute previous_id = lag(id).
exe.
SPSS Lag - Creating a Counter
A great way to illustrate how LAG works is to create a counter variable. For each id value we'll create a variable that indicates its nth row of data. We'll start by identifying the first record of each id by using an IF command as shown in the syntax below. How it works is illustrated by the screenshot.
if $casenum = 1 or id ne lag(id) counter = 1.
exe.
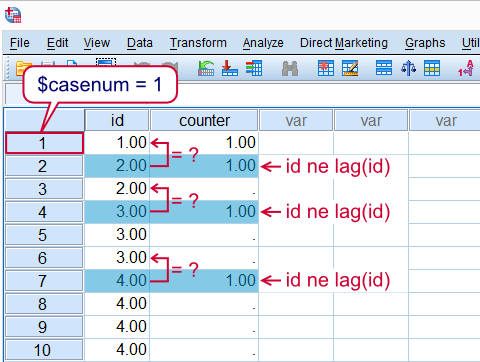 Identify first row for each id value
Identify first row for each id value
Next we'll finish our counter. What's important to understand here is that cases are processed sequentially from top to bottom when SPSS executes data transformations. That is, SPSS will start at $casenum = 1 and work its way down case by case. So a value created by LAG during this process may be used by the next case. The screenshot below illustrates three of the steps that occur while SPSS processes the syntax below.Since these steps usually require milliseconds to complete you don't actually see them occurring in normal situations.
if sysmis(counter) counter = lag(counter) + 1.
exe.
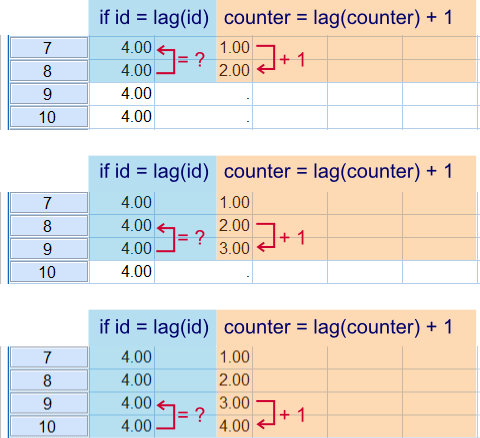 SPSS processes cases sequentially from top to bottom
SPSS processes cases sequentially from top to bottom
SPSS Long Data Format
 SPSS Long Data Format. Note how each customer can have one or more records.
SPSS Long Data Format. Note how each customer can have one or more records.
We'll continue with real world examples that gradually increase in level. Say we have data holding orders as records as in the figure above. Note that each customer can have one or several rows of data. This format is often referred to as a long data format.The opposite of this, with each customer's data on a single row, is called a wide data format. Relevant questions regarding these data may be
- How often do customers place an order? Or alternatively, how many days pass between orders by one customer?
- How many orders does the average customer place?
- How much money do customers spend?
We'll walk through these questions using the LAG function for answering them.
SPSS LAG Example - Days Between Orders
Running the syntax below will create the data from the previous screenshot and find the days between orders by one customer. Note that the records must first be sorted in a meaningful way. Next, if customer_id = lag(customer_id) checks whether each record is not the first record for a given customer. Only for these records days_between_orders will be calculated.
SPSS LAG Syntax Example 2
data list free / order_id (f2.0) order_date(edate10) customer_id invoice_amount (2f3.0).
begin data
1 26.09.2011 8 100 2 30.10.2011 8 100 3 28.12.2011 3 100 4 21.01.2012 12 150 5 26.01.2012 3 110
6 31.01.2012 7 140 7 16.02.2012 12 190 8 22.02.2012 12 30 9 23.02.2012 3 150 10 04.04.2012 12 50
end data.
*2. Sort records by customer_id and then order_date.
sort cases customer_id order_date.
*3. Compute days between orders by single customer.
if customer_id = lag(customer_id) days_between_orders = datediff(order_date,lag(order_date),'days').
exe.
SPSS LAG Example - Cumulative Orders per Customer
Now we'll create a cumulative order count per customer. We'll first set this new variable to 1 for each customer's first record. This is selected by if $casenum = 1 or lag(customer_id) ne customer_id. Next, we'll add 1 to it for each consecutive record if it belongs to the same customer. This condition is implied by if customer_id = lag(customer_id) Note that we make use of the fact that SUM(SYSTEM MISSING,X) = X. We can't use the + operator here because SYSTEM MISSING + X = SYSTEM MISSING.
SPSS LAG Syntax Example 3
if $casenum = 1 or lag(customer_id) ne customer_id cumulative_orders = 1.
exe.
*2. For each consecutive record, add 1 to cumulative_orders.
if customer_id = lag(customer_id) cumulative_orders = sum(lag(cumulative_orders),1).
exe.
SPSS LAG Example - Cumulative Expenditure
Finally we'll create the cumulative expenditure. This works quite similarly to the previous example. Instead of adding 1 to each consecutive record, we now add invoice_amount.
SPSS LAG Syntax Example 4
if $casenum = 1 or lag(customer_id) ne customer_id cumulative_amount = invoice_amount.
exe.
*2. Cumulative amount for second through nth records.
if customer_id = lag(customer_id) cumulative_amount = sum(invoice_amount,lag(cumulative_amount)).
exe.
 Original variables and those created by using LAG
Original variables and those created by using LAG
Notes
- As a rule of thumb, always run
EXECUTEimmediately after commands usingLAG. This is one of the very few cases where you really need to runEXECUTEor a procedure.The reason for this is rather technical but for those who wonder:LAGis always carried out after all other transformations. This means that the order in which commands are executed may deviate from the order in which they're specified. So if a variable affected byLAGis used in a subsequent command, the latter is likely to use the ‘wrong’ values becauseLAGhasn't taken place yet. - In order to get the value of the nth previous case, use
LAG(...,n). Note thatnmust be a positive integer. That is, you can't useLAG(v1,-1)for getting the value from the next instead of the previous case.
Getting Values from Next Cases
LAGcan't readily access values from next rather than previous cases. If you do need the value of a next case, one option is to reverse the order of the cases and useLAGanyway.- You can also get values from next cases with
CREATEorSHIFT VALUES. Note that these are procedures (and not functions). This means you can't use them in anIFcommand for evaluating conditions like we did in most of the examples discussed in this tutorial.
Additional Examples
Shortly after writing this tutorial we received some more challenging questions that are solved by using mainly LAG and IF statements. We'll walk through them below.
SPSS Lag - Identifying Sessions
“We held an experiment in which respondents were presented with random pictures. Each picture may or may not occur repeatedly. Subsequent presentations of a single picture constitute a session. How can we add these sessions to our data?”
The syntax below focuses on explaining how things work, step by step. It's not the fastest option for answering the question.For one way to shorten it, see Compute A = B = C.
SPSS LAG Syntax Example 5
data list free / sequence id picture.
begin data.
1 1 1 2 1 4 3 1 3 4 1 4 5 1 4 6 1 4 7 1 1 8 1 1 9 1 3 10 1 3 1 2 3 2 2 3 3 2 3 4 2 4 5 2 2 6 2 4 7 2
1 8 2 2 9 2 3 10 2 1 1 3 1 2 3 3 3 3 3 4 3 4 5 3 4 6 3 2 7 3 1 8 3 4 9 3 3 10 3 3
end data.
variable labels id 'Respondent id'.
*.2 Session = 1 for every respondent's first row of data.
if $casenum eq 1 or id ne lag(id) session = 1.
exe.
*3. Detect switches (different picture for same respondent).
if $casenum gt 1 and id eq lag(id) and picture ne lag(picture) switch = 1.
exe.
*4. Increase session with 1 for every switch.
if $casenum ne 1 and id eq lag(id) session = sum(lag(session),switch).
exe.
*5. Optionally, delete "switch".
delete variables switch.
SPSS Lag - Count Votes in Households
“We collected data on different people in households. One of our variables, vote is the political party each respondent would vote for when asked. We'd like to estimate the political heterogeneity of households by counting the number of different values on vote. How can we do this?”
Note the use of AGGREGATE in step 6. As with the previous example, this syntax could be shortened.
SPSS LAG Syntax Example 6
data list free / household_member household vote.
begin data
1 1 4 1 2 3 2 2 3 3 2 1 4 2 1 5 2 4 1 3 3 2 3 4 1 4 1 2 4 4 1 5 2 2 5 2 3 5 3 4 5 4 5 5 1
end data.
*2. Sort by household, then vote.
sort cases by household vote.
*3. For first member of household, counter = 1.
if $casenum = 1 or household ne lag(household) counter = 1.
exe.
*4. Identify switches (vote changes within household).
if $casenum ne 1 and household = lag(household) and vote ne lag(vote) switch = 1.
exe.
*5. Increase counter by 1 for every switch.
if $casenum ne 1 and household = lag(household) counter = sum(lag(counter),switch).
exe.
*6. Different votes in household = max(counter).
aggregate outfile = * mode addvariables
/break household
/different_votes_in_household = max(counter).
*7. Optionally delete temp helper variables.
delete variables counter switch.
SPSS LOOP – Quick Tutorial & Examples
LOOP is a command for running one or many SPSS transformation commands repetitively. SPSS LOOP is often used together with VECTOR. An (often) easier alternative is DO REPEAT.
- There are several ways for looping in SPSS. It depends on the specifics of the situation which one(s) you can use. Note that these options are only available in syntax.
- An option for looping over transformations is the LOOP command. We'll explain it with some examples a bit later in this tutorial.
- A second option for transformations is the DO REPEAT command.
- For looping over procedures, the way to go is Python. For a very basic example, see Regression over Many Dependent Variables.
Example: Replacing Double by Single Spaces
- Say we have data containing sentences. The sentences contain double, triple (and so on) spaces which we'd like to replace by single spaces.
- Test data for this example are created by running the syntax below.
data list free/sentence(a45).
begin data
'a b c d e f g h i'
end data.
SPSS LOOP - Minimal Specification
- Note that simply replacing double spaces by single ones won't be sufficient. This is because 'new' double spaces may be created by the replacement process if it encounters triple(+) spaces.
- However, if we perform this replacement repeatedly, all double spaces will at some point be gone. The most basic way for doing this is simply putting the replacement in a loop.
- The SPSS LOOP command indicates that subsequent commands should be repeated. Reversely, END LOOP indicates that commands following it do not have to be repeated.
- The syntax below demonstrates the most basic use of LOOP. We'll use REPLACE for removing double spaces.
SPSS LOOP Syntax Example 1
loop.
compute sentence = replace(sentence,' ',' ').
end loop.
execute.
The LOOP Index Variable
- The preceding syntax example will do its job but it's very inefficient and even raises a warning (#534). This is because nothing tells SPSS to stop looping at some point except for a predefined maximum number of loops.
- A very basic way to circumvent this is to use a loop index variable. This is a variable whose values change over iterations. Like so we can specify exactly how many iterations we'd like over our command(s).
- Assuming our sentence does not hold more than 8 spaces in a row, we'll need to repeat our replace command only 3 times. On the first iteration, 8 or 7 adjacent spaces will become 4 spaces. The second iteration will replace these 4 spaces with two spaces. The 2 spaces will be replaced by a single space on the last iteration.
- For a demonstration, recreate the test data from the first example and try the syntax below.
SPSS LOOP Syntax Example 2
loop repetition = 1 to 3.
compute sentence = replace(sentence,' ',' ').
end loop.
execute.
LOOP Index as Scratch Variable
- The example above basically works as follows: the variable 'repetition' takes on the value 1 and the replace command is performed. Next, it takes on the value 2 and the replace command is performed a second time. 'Repetition' becomes 3 and the third iteration takes place.
- Next, 'repetition' becomes 4 but since this exceeds the threshold of 3 that we set, the loop stops and the replace command is not carried out a fourth time.
- Three iterations are exactly enough for the data at hand. However, we do end up with a useless loop index ('repetition') in our data. We could delete it after the loop but a more common solution is to ensure it doesn't show up in the first place.
- This is done by using a scratch variable as the loop index. In a nutshell, just start the variable name with "#" and it won't show up.
- Like so, you could use #repetition instead of repetition. In practice you'll often see #i (i for index) being used as the loop index. However, just
#is also a valid name for a scratch variable so we'll stick with that. - These points are demonstrated in the syntax below.
SPSS LOOP Syntax Example 3
loop # = 1 to 3.
compute sentence = replace(sentence,' ',' ').
end loop.
exe.
END LOOP IF
- The last syntax example wasn't too bad but it has two problems. First, we need to know in advance how many loops we'll need. This is not always the case. To ensure sufficient iterations, we could simply loop a large number of times but this may slow down the process on large datasets.
- Second, if there are many cases then perhaps some need more iterations than others.
- Both points can be taken into account by dropping the loop index. Instead, we'll end the loop as soon as there's no more double spaces for each case. During each iteration we'll check whether this is the case by using the INDEX function which will return 0 when the double space is not present. The syntax below demonstrates this.
SPSS LOOP Syntax Example 4
loop.
compute sentence = replace(sentence,' ',' ').
end loop if char.index(sentence,' ') = 0.
exe.
LOOP IF
- The previous syntax example still has a tiny shortcoming: it will perform the replace command even if no double spaces are present in a sentence at all.
- A more efficient approach is to only start the loop for cases containing at least one double space. So for some cases zero iterations will take place while for others three (or more) iterations may be carried out.
- This is accomplished by using LOOP IF. The condition for looping is the presence of a double space. The syntax below demonstrates this.
SPSS LOOP Syntax Example 5
loop if char.index(sentence,' ') > 0.
compute sentence = replace(sentence,' ',' ').
end loop.
exe.
Using the LOOP Index
- The previous syntax examples using a loop index didn't use this index within the commands that were repeated. It merely indicated a fixed number of repetitions for each case.
- However, it's common that the index itself is used within the loop as well. Over the iterations, the index is replaced by each of the numbers that's being looped over.
- This is demonstrated in the syntax below (using different test data than the previous examples). It will count the occurrence of the letter 'e' in each name. For each case the number of iterations is equal to the number of letters in their name.
- If you're unfamiliar with the string functions used in the example, see our SPSS String Variables Tutorial.
SPSS LOOP Syntax Example 6
data list free/name(a10).
begin data
Anneke Martin Stefan
end data.
*2. Count occurrence of 'e' by looping through letters in name.
compute count_e = 0.
loop # = 1 to char.length(name).
if char.substr(name,#,1) = 'e' count_e = count_e + 1.
end loop.
exe.
The BY Keyword
- When a loop index is used, it may increment/decrement in steps smaller or larger than one. This is specified by the BY keyword.
- For instance, 3 TO 12 BY 3 increments from 3 through 12 by steps of 3. It thus returns 3, 6, 9 and 12.
- When combined with VECTOR, this can be used to compute means over groups over variables. Like so, the final syntax example calculates means over (v1, v2, v3), (v4, v5, v6) and so on.
SPSS LOOP Syntax Example 7
data list free/v1 to v12 (12f1.0).
begin data
0 0 0 0 0 1 0 1 1 1 1 1
end data.
*2. Compute 4 sums, each over 3 adjacent variables.
vector v = v1 to v12 / s(4).
loop # = 3 to 12 by 3.
compute s(# / 3) = sum(v(#),v(# - 1),v(# - 2)).
end loop.
exe.