1. SPSS Case Count and Variable Count
(Overview and data file are found here.)
The very first thing we want to know about basically any data file, are its dimensions: how many cases and how many variables does it contain? For a quick case count, select any cell in data view and press the CTRL + ![]() shortkey. Alternatively, just scroll all the way down with the scroll bar.
shortkey. Alternatively, just scroll all the way down with the scroll bar.
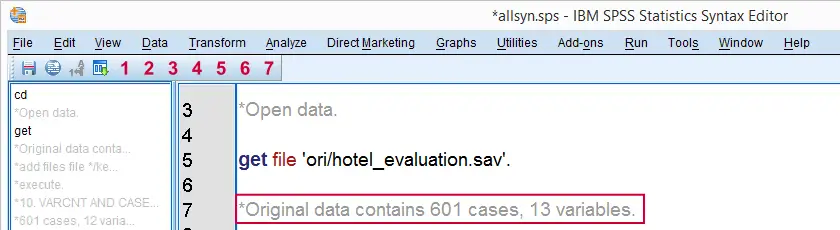
Our file contains 601 cases. Applying the same method in variable view tells us that we have 13 variables. Since we may at some point delete some cases and/or variables, we personally like to add a comment to our syntax file on the original dimensions. The screenshot below shows what it looks like.
2. Unique Case Identifier Variable
(Overview and data file are found here)
Data files may or may not have a unique case identifier variable: a variable with a distinct value for every case. In some cases, a combination of two (or more) variables serves this purpose.
It's a good idea to have a unique identifier for three reasons: first, if you remove variables from your data because they don't seem relevant, you can later decide to merge them back in as shown in MATCH FILES. Second, if a case contains some unusual value, you can correct it if you can address this -and only this- case. Third, a single identifier may be used in various data sources containing similar records. If so, having this identifier in your data enables you to merge your (edited) data with these other data sources.
Our data seems to contain id as a unique case identifier. But how can we be really sure that none of its values occur more than once? The syntax below does so by using AGGREGATE.
aggregate outfile * mode addvariables
/break id
/cnt = n.
*2. If cnt contains only 1, every value of id occurs once and hence it's a unique identifier.
frequencies cnt.
Result

This frequency table tells us that the only value in this variable is 1. Hence, we do indeed have a unique case identifier. Otherwise, the second best option is to create one before doing anything else with the data. The syntax below shows one option for doing so, using the outline numbers in data view, known as $casenum.
compute ident = $casenum.
execute.
THIS TUTORIAL HAS 8 COMMENTS:
By Jeanette on October 23rd, 2015
How would you handle it if persons where allowed multiple attempts at completing a survey? Is there a way to combine their attempts such that there is only one record remaining for each person.
By Ruben Geert van den Berg on October 24th, 2015
Thanks for your comment, good question! What to do exactly depends on your data.
If you have a unique identifier variable for each respondent (not attempt!) and each attempt results in a case (row of data values in SPSS), then you can probably solve the problem with AGGREGATE. Use the respondent identifier as the BREAK variable and create the MAX over all relevant variables.
But I'd need to see the actual data to confirm this works for your particular case.
By Maliha on November 23rd, 2015
1.How to analyeze data across two files in spss?
2.How to compare two or more files in spss?
By Ruben Geert van den Berg on November 23rd, 2015
Thanks for your comment! These are rather elaborate questions but a likely strategy for both is to merge the files using ADD FILES. Make sure both files contain a
sourcevariable that indicates the source (file 1 or file 2) for each case.Now you can readily create basic tables such as CROSSTABS and MEANS for comparing variables between the two files. Most basic graphs found under "legacy dialogs" in recent SPSS versions allow for a column variable. Specifying the source variable here results in nice graphs with two (or more) panes as shown in this illustration.
Hope that helps!
By Neha on April 1st, 2016
Impressive!!