SPSS DESCRIPTIVES generates a single table with descriptive statistics for one or more variables. It can also add z-scores to your data. We'll walk through its major options using freelancers.sav. The screenshot below shows part of its data view.
User Missing Values
Before running any descriptives, we first need to specify some user missing values for income_2010 through income_2014. We'll do so by running the syntax below. The FORMATS command suppresses excessive decimal places for output tables that we'll generate later on.
missing values income_2010 to income_2014 (1000000 thru hi).
*Hide decimal places for income_2010 through income_2014.
formats income_2010 to income_2014 (dollar8).
SPSS DESCRIPTIVES - Basic Use
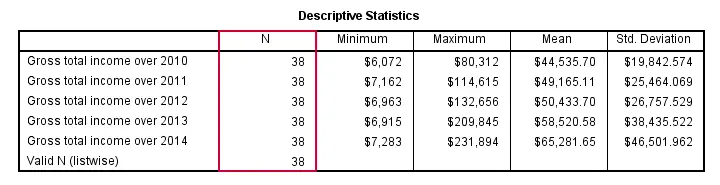
The most basic way to run a descriptives table is simply “DESCRIPTIVES” followed by one ore more variable names (possibly using TO or ALL) and a period. The syntax below gives an example.
descriptives income_2010 to income_2014.
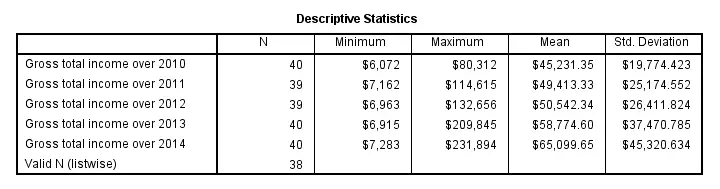
Note that “Valid N (listwise)” denotes the number of cases that don't have any missing values on any of the variables shown in the table.
SPSS DESCRIPTIVES - STATISTICS Subcommand
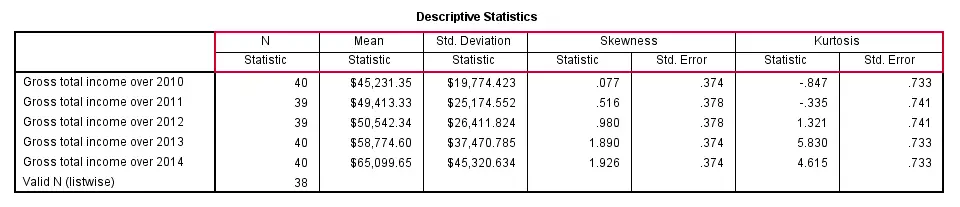
Statistics and the order in which they'll appear in the table can be specified by adding a STATISTICS subcommand. However, the first column for descriptives is always N, even if not specified.
Note that some statistics (such as skewness and kurtosis) will always be followed by their standard error, which can't be specified separately.If this is not to your liking, try MEANS instead. Note that for MEANS, statistics are specified on a CELLS subcommand; STATISTICS refers to test statistics for significance tests here.
descriptives income_2010 to income_2014
/statistics mean stddev skewness kurtosis.
SPSS DESCRIPTIVES - SORT Subcommand
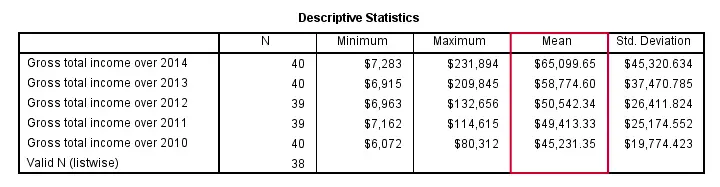
By default, table rows (representing variables) are sorted by the order in which these variables are specified in DESCRIPTIVES. This can be changed by specifying a statistic (or NAME for variable names) on a SORT subcommand. Add “(d)” for sorting descendingly.
descriptives income_2010 to income_2014
/sort mean(d).
SPSS DESCRIPTIVES - MISSING Subcommand
By default, DESCRIPTIVES uses pairwise deletion of missing values: for each variable, all cases having a valid value on this variable are used.Since “deletion” doesn't actually delete anything, “exclusion” would be more appropriate here. This is why N may differ for different variables.
Specifying LISTWISE on a MISSING subcommand implies listwise deletion of missing values: for all variables, only cases are used that don't have any missing value on any of these variables.
descriptives income_2010 to income_2014
/missing listwise.
SPSS DESCRIPTIVES - Z-Scores
Standardizing variables mean rescaling them so that they have a mean of 0 and a standard deviation of 1. This is done by subtracting a variable's mean from each separate value and dividing the remainder by the variable's standard deviation. The resulting values are called z-scores.
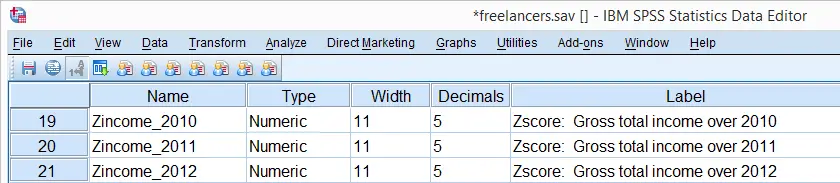
DESCRIPTIVES offers two ways for adding z-scores to your data. First, adding a SAVE subcommand standardizes all variables on the DESCRIPTIVES command. The names for these new variables are the original variable names prefixed by “Z”. The screenshot below shows the result in data view.
descriptives income_2010 to income_2014
/save.
A second option here is adding variable names for the new (standardized) variables behind the original variable names, enclosed by parentheses.
descriptives income_2012 (z2) income_2013 (z3).

Note that either option for standardizing variables leaves the original variables intact. Second, DESCRIPTIVES automatically adds variable labels to the newly added standardized variables.
Z-Scores - Cautionary Note
Whenever adding z-scores to your data with DESCRIPTIVES, keep in mind that the result may be affected by the missing subcommand. Also, FILTER, SPLIT FILE or WEIGHT being in effect may influence the calculation of z-scores. This may or may not be your intention.
Recent SPSS versions will show in the status bar whether these are in effect. However, if you want to be really sure, simply run
show filter split weight.
just before standardizing variables to stay on the safe side.

THIS TUTORIAL HAS 1 COMMENT:
By Michael Njobvu on June 6th, 2018
It's great indeed! All these tutorials are simply fantastic for beginners as well as those who have long forgotten. Keep posting these valuable short lessons. I had a serious challenge but now am feeling safe. At my place of work, those who know the staff brag and cannot even show you what they are doing. They