Summary
This tutorial walks you through opening a .csv data file in SPSS. We chose a .csv file as obtained from Google Analytics (GA). Since many readers may be unfamiliar with GA, the screenshot below gives a basic idea of what the data look like before we export them as a .csv file.
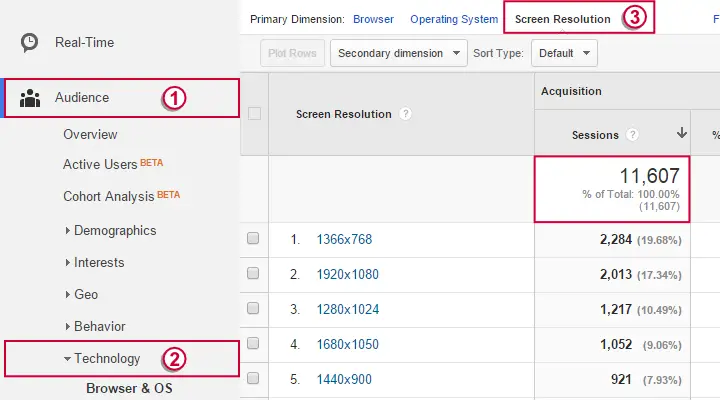
The original data file -as generated by GA- can be downloaded here. We chose it because opening it in SPSS causes some complications that you'll typically encounter with real life data. We'll take our time to explain and resolve these issues.
Notepad++
Right, so where do we start? Well, .csv files are typically associated with spreadsheet editors such as MS Excel or OpenOffice Calc. However, a better idea is to inspect the file with notepad++ or a similar text editor. As we'll see in a minute, this allows us to gather some essential pieces of information on the file contents. The screenshot below shows what the data look like in Notepad++.
Contents of the CSV file
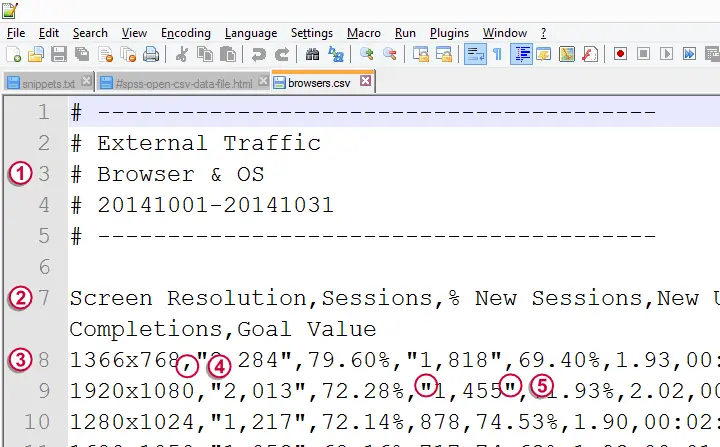
 Note that the first 6 lines of the file are a basic description of the data. We'll remove them after inspecting the rest of the data.
Note that the first 6 lines of the file are a basic description of the data. We'll remove them after inspecting the rest of the data.
 Line 7 contains variable names. Note that most of them are not suitable for SPSS because they contain spaces or start with a percent sign. We'll clean them up manually.
Line 7 contains variable names. Note that most of them are not suitable for SPSS because they contain spaces or start with a percent sign. We'll clean them up manually.
 The actual data start on line 8, which will be the second line of data after removing the first 6 lines.
The actual data start on line 8, which will be the second line of data after removing the first 6 lines.
 Note how data values are separated by commas (hence “comma separated values” or .csv file). These commas are known as the delimiter.
Note how data values are separated by commas (hence “comma separated values” or .csv file). These commas are known as the delimiter.
 If a value contains a comma, there's double quotes around it. This is the text qualifier. These quotes indicate that commas between them are not meant as delimiters.
If a value contains a comma, there's double quotes around it. This is the text qualifier. These quotes indicate that commas between them are not meant as delimiters.
More Contents of the CSV file
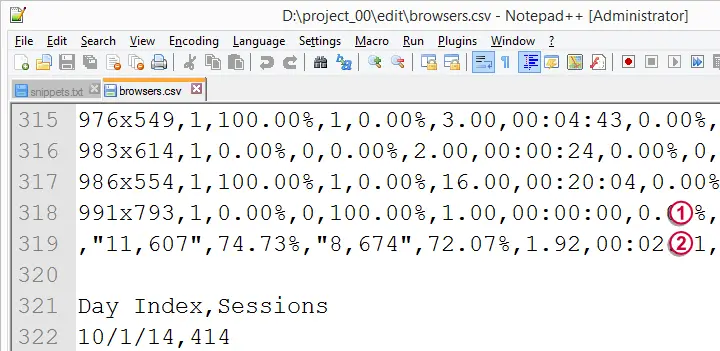
If we quickly scroll down the file (tip: use the pgdn key on your keyboard), we see that line 318 is the last line containing raw data values.
Lines 319 and below contain summary statistics which are not part of the data we want. We therefore remove them.

Last but not least, note “UTF-8” in the status bar. This is the file encoding. It basically tells how characters are mapped onto the bits (ones and zeroes) that the file really consists of.
Cleaning Up the CSV File
We now clean up the .csv file like we just discussed. After doing so, we'll save it with a different file name. This enables us to compare our manually edited file with the original file as GA generated it. The final .csv file that we'll open in SPSS can be downloaded from browsers.csv.
Opening the CSV File in SPSS
We're now ready to open our .csv file in SPSS. For doing so, we'll first launch SPSS and navigate to
![]()
![]() .
.
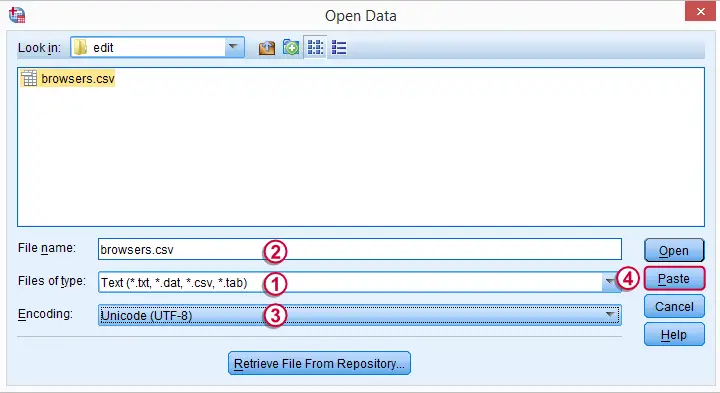
We saw in Notepad++ that the file encoding is UTF-8. When we select the file, SPSS may switch to “Local Encoding” here. If that happens, set it back to UTF-8 before proceeding.
Click instead of .
Step 1
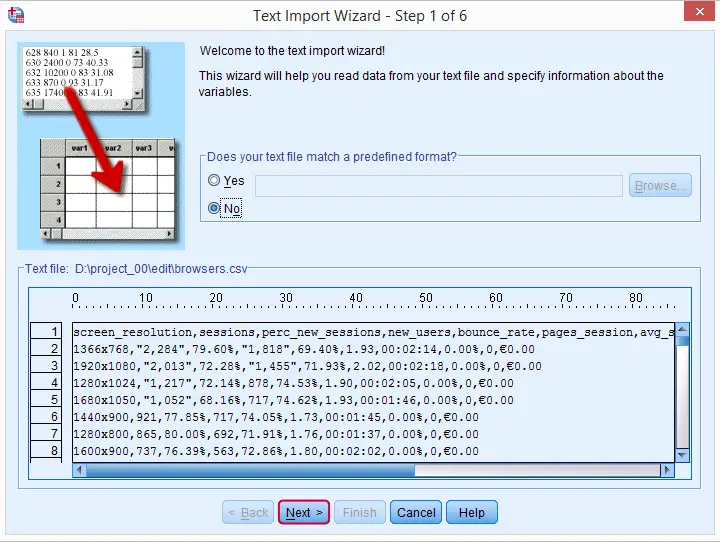
Step 2
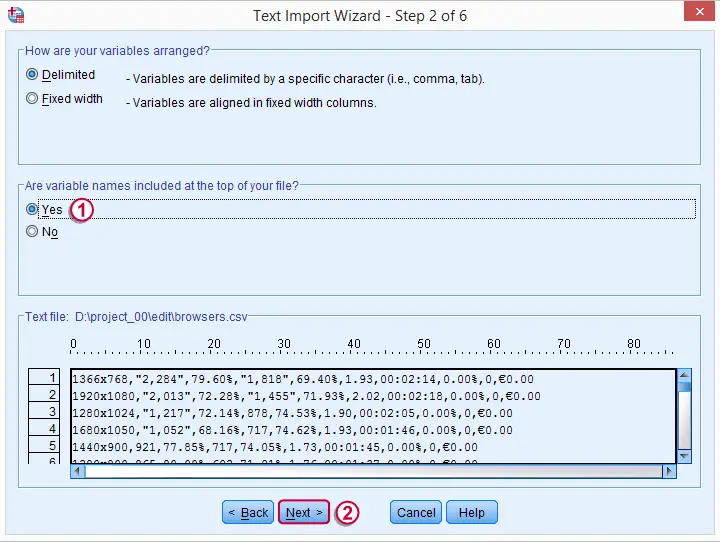
Remember that variable names make up the first line of our .csv file.
Step 3
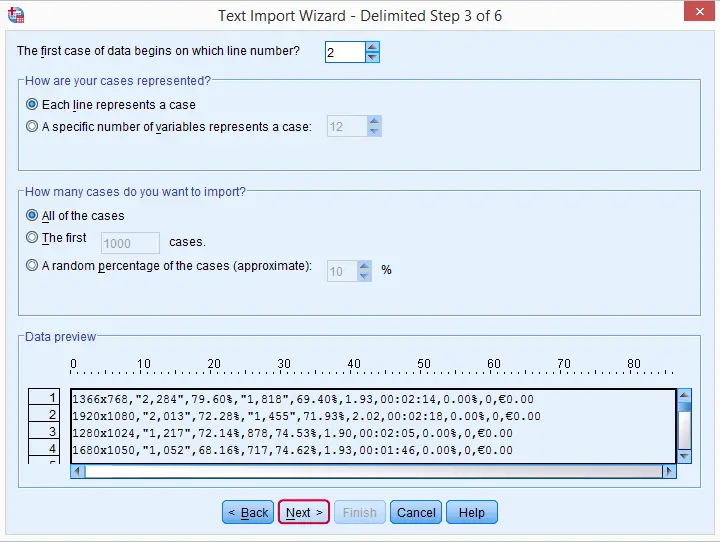
Step 4
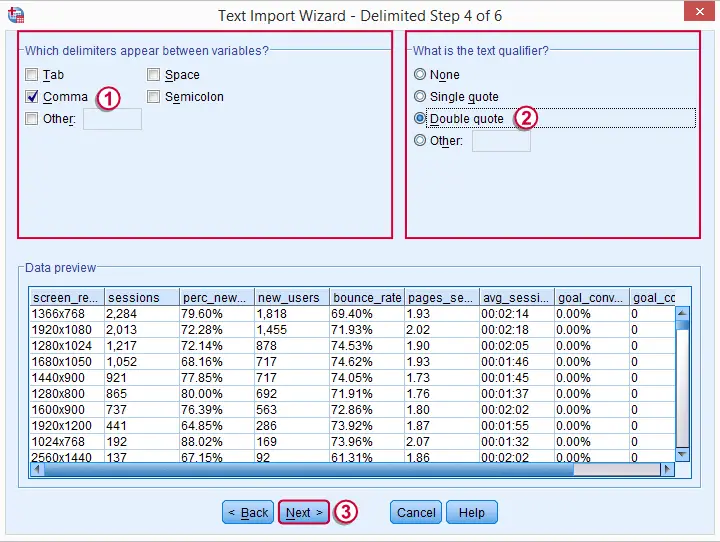
Here we specify the delimiter we identified when we inspected the file in Notepad++.
Like we saw earlier, the only text qualifier in our raw data is a double quote.
Step 5
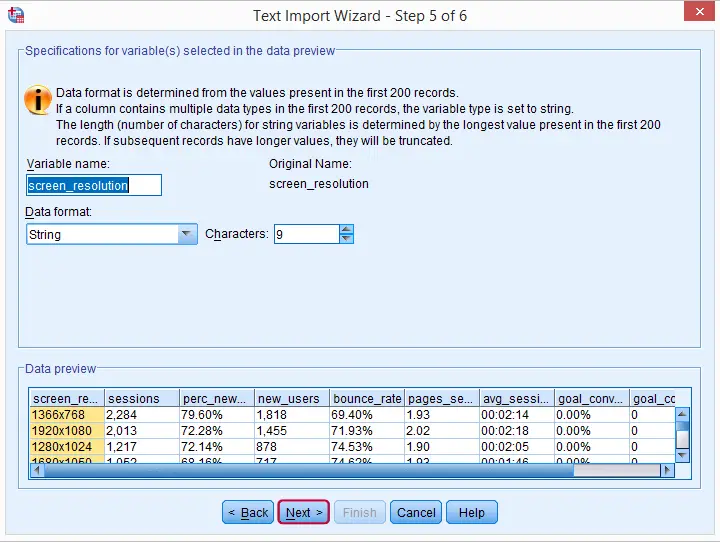
We could specify some variable formats here. However, taking care of that later yields better results faster.
Step 6
Initial Syntax
Following the previous steps results in the syntax below. Readers who'd like to copy-paste the syntax from this tutorial may either correct the /FILE specification (second line of syntax) or create a folder d:/project_00/edit and move browsers.csv into this folder.
Before running this syntax, we remove the last line; we didn't ask for any DATASET NAME ... command and running it just gets in our way.
GET DATA /TYPE=TXT
/FILE="D:\project_00\edit\browsers.csv"
/ENCODING='UTF8'
/DELCASE=LINE
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/IMPORTCASE=ALL
/VARIABLES=
screen_resolution A9
sessions F5.0
perc_new_sessions A7
new_users F5.0
bounce_rate A7
pages_session F4.2
avg_session_duration A8
goal_conversion_rate A5
goal_completions F1.0
goal_value A7.
CACHE.
EXECUTE.
DATASET NAME DataSet1 WINDOW=FRONT.
System Missing Values
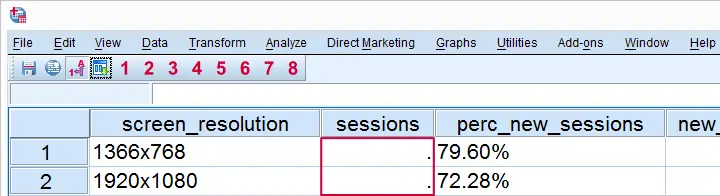
After running the syntax, let's take a look at data view. Note that there's some system missing values in sessions. The reason for this is that some values contain commas. If we take a close look at the syntax, we see that it contains sessions F5.0 This means that the values of the variable sessions are interpreted according to a f format (standard numeric) which doesn't understand commas. The solution is replacing this line by sessions comma6 We do so for all standard numeric variables. Don't worry if you're not sure which variables that refers to; we'll present the entire corrected syntax in a minute.
String Variables
The other variables may look fine at first, but inspecting variable view shows many of them to be string variables. If we think about the data for a minute, we conclude that screen_resolution should be the only string variable here.
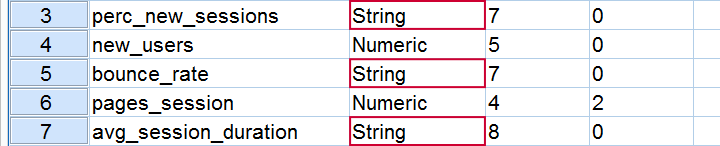
This is the same problem -and the same solution- as the system missing values we saw earlier. For instance, we find perc_new_sessions A7 in our syntax. The A format indicates a string variable and SPSS has chosen this format here because of the percentage signs in the data. The solution is replacing the line by perc_new_sessions pct7.2 In a similar vein, we choose this format for all percentage variables. Again, we'll present the entire corrected syntax in a minute.
Time Variables
Our data contain one time variable: avg_session_duration. Our syntax addresses it as avg_session_duration A8 Our time values are in hh:mm:ss format. In SPSS, this is the time8 format (where 8 denotes the number of characters including the colons). We therefore replace the previous line by avg_session_duration time8
Final Corrected Syntax
After making all modifications as previously explained, we end up with the syntax below. This is the final syntax we'll use for opening the .csv file in SPSS.
GET DATA /TYPE=TXT
/FILE="D:\project_00\edit\browsers.csv"
/ENCODING='UTF8'
/DELCASE=LINE
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/IMPORTCASE=ALL
/VARIABLES=
screen_resolution A9
sessions comma6
perc_new_sessions pct7.2
new_users comma6
bounce_rate pct7.2
pages_session F4.2
avg_session_duration time8
goal_conversion_rate pct7.2
goal_completions F1.0
goal_value A7.
CACHE.
EXECUTE.
Euro Signs
Attentive readers may notice that we didn't prevent goal_value from ending up as a string variable. This is because the previous steps couldn't prevent this. For the sake of completeness, we'll fix it with the syntax below.
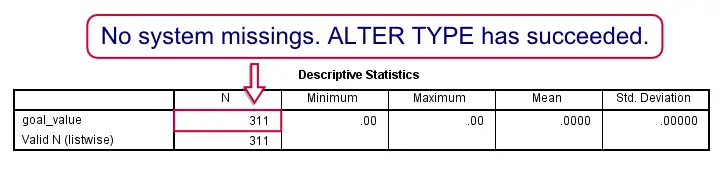
As explained elsewhere, we always make sure that ALTER TYPE doesn't create any system missing values. We do so in step 3.
Syntax for Fixing Euro Signs
compute goal_value = char.substr(goal_value,2).
execute.
*2. Convert to numeric variable.
alter type goal_value(f4.2).
*3. Confirm that all 311 values are non missing.
descriptives goal_value.
*4. Set cca (Custom Currency A) to Euro.
set cca '-,€ ,,'.
*5. Set goal_value to cca.
formats goal_value(cca6.2).
*Done.
Result
Extracting Screen Width
That's it. We now have a perfect SPSS file holding our .csv data. If that's all you wanted to know, you can stop reading right here, right now.
Right, note that the values of screen_resolution consist of two numbers separated by an x. The first number is the screen width in pixels and we'll extract it by running the syntax below.
compute pos_x = char.index(screen_resolution,'x').
execute.
*2. Create new, empty string variable.
string width(a5).
*3. Compute width = characters of screen_resolution up to position of "x".
compute width = char.substr(screen_resolution,1,pos_x - 1).
execute.
*4. Change width to numeric variable.
alter type width(f5).
*5. Make sure ALTER TYPE doesn't create system missing values.
descriptives width.
*Done.
Cumulative Percentages of Sessions per Screen Width
Finally. We're ready to create the table we're after: we'd like to know the cumulative percentages of sessions per screen width, from largest to smallest. Note that most cases represent many sessions. In order to have SPSS interpret each case as the number of sessions it represents, we'll use WEIGHT as shown below.
Finally, we'll run a FREQUENCIES table which we'll sort according to descending screen width.
SPSS Syntax for Cumulative Percentages
weight by sessions.
*2. Create frequencies table, sort by descending widths.
frequencies width/format dvalue.
Checksum

Due to weighting our cases, SPSS reports 11,607 cases. This is the exact same number of sessions that we saw in the Google Analytics (GA) interface (very first screenshot). We can see this as a checksum: these numbers being identical strongly suggests that our SPSS data perfectly correspond to the original GA data.
Purpose
The purpose of this study was to choose a minimal screen width that our website design should support. Due to the nature of our website, very few visitors use a small screen width (smartphone or tablet). Should we invest in supporting mobile devices instead of writing more tutorials? Our final table suggests we shouldn't.
Conclusion
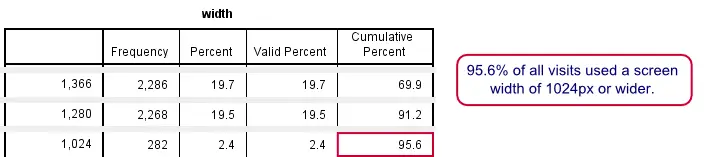 Most Interesting Sections from Final Table
Most Interesting Sections from Final Table
The second table is rather large but this doesn't bother us. If we inspect the cumulative percentages and scroll down, we conclude that 69.9% of all sessions used a screen width of 1,366 pixels or more. A screen width of at least 1,280 pixels was used in 91.2% of all sessions.
Finally, if we make sure our website works well at a screen width of 1,024 pixels or more, we support 95.6% of all visits. Our final decision was to support screen widths of 800 pixels or more because it's the smallest our design could reasonably handle.
THIS TUTORIAL HAS 3 COMMENTS:
By Isabel on June 8th, 2016
This is very helpful! However, what can I do when my dataset is too big for Notepad? I really only need to change the variable names. Is there a way I can tell Notepad to copy in some portion of the file that then could be properly imported via Text Wizard into SPSS?
By Ruben Geert van den Berg on June 8th, 2016
Hi Isabel!
Thanks for your comment. Do you mean ordinary Notepad or Notepad++?
Anway, if you know at which line your data values start, you can perhaps select "no variable names at top of file" and set the first row of data to the first line of actual data values. I believe SPSS will then generate default variable names which are changed most easily in the generated syntax.
Oh, note that a "wrapped" line still counts as one line. In notepad++, use the numbers in the left margin for determining the line numbers. I should add that Notepad++ is one of my favorite software packages of all times and has some amazing shortkeys. I basically wrote this entire website with it.
By Ralf on May 16th, 2017
We got some strange error messages:
>Warnung. Befehlsname: GET DATA
>Undefined error #2283 - not found in file "C:\PROGRA~1\IBM\SPSS\STATIS~1\22\lang\de\txtwdac.err"
Could you please tell me where to find help please ? There couldn't be found any hint.
Regards
Ralf