While working in SPSS, it's pretty common to reorder your variables. This tutorial shows how to do so the right way. We encourage you try the examples for yourself by downloading and opening hotel_evaluation.sav, a screenshot of which is shown below.
SPSS Reorder Variables Example 1
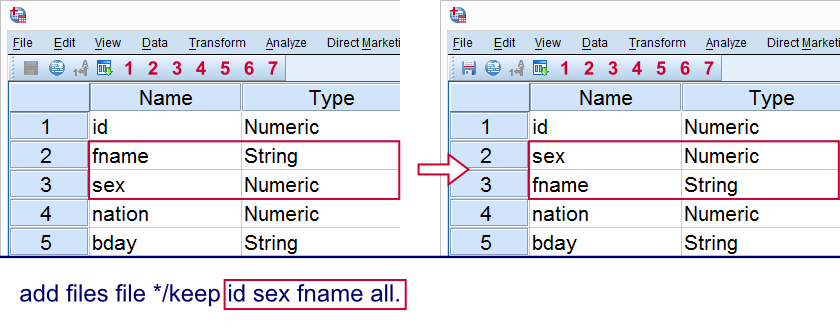
Right, the most common way for reordering variables in SPSS is by running ADD FILES. Before explaining how it works, let's first show that it works in the first place. So suppose we'd like to swap the variables fname and sex. Running the syntax below does just that.
add files file *
/keep id sex fname all.
execute.
Result
How Does It Work?
Remember that ADD FILES merges data sources holding different cases but similar variables. Note that in SPSS syntax, an * addresses the active dataset (often the only data that's open in SPSS).
Now, if we specify this as the only data source, it gets merged with nothing. This means that running
add files file *.
does absolutely nothing whatsoever. However, this command becomes useful if we add a /keep subcommand which tells SPSS which variables to keep (not delete) and in which order.
In our first example, we decided to keep id sex fname. Note that the original order here was id fname sex.
Finally, all is a special keyword that addresses all other variables in their original order. Omitting all deletes these variables from our data. The final result of all this is that we basically do nothing except keep all variables in a different order than previously, which is exactly what we were intending.
SPSS Reorder Variables Example 2
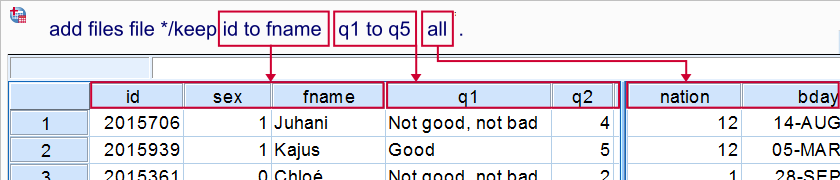
Right, we just swapped two variables in our data. But what about moving entire blocks of variables? For instance, suppose we want to have variables q1 through q5 right after fname in our data. Well, this doesn't pose any challenge whatsoever if we use SPSS’ TO keyword. The syntax below shows just how easily it's done.
add files file */keep id to fname q1 to q5 all.
execute.
Result
SPSS Reorder Variables Example 3
Recap: if we're having some data open in SPSS, we can easily reorder our variables by using an ADD FILES command with a keep subcommand.
Is that the only way to get it done? Well, no. If we're done with a dataset, we may use the exact same keep subcommand in a save command as shown below (first example). This is never really necessary but it may save a tiny amount of syntax and processing time.
Just for the sake of completeness, if we know in advance which variables are present in our data, we may also reorder them while opening the data file with get.
SPSS Reorder Variables Syntax Examples
save outfile '10_all_data_prepared.sav'
/keep q1 to q5 all.
*2. Reorder variables when opening data file.
get file 'hotel_evaluation.sav'
/keep q1 to q5 all.
SPSS SORT VARIABLES
There's just one more thing that we need to mention: SPSS (starting from version 16) also has a SORT VARIABLES command. Like so you can sort variables according to variable name, variable type, variable label, format or a couple of other properties.
We obviously needed to mention this command here. However, we very rarely use it in practice. The reason is that the aforementioned sorting options virtually never correspond to the order we desire for our variables. Those who like to give it a quick try anyway, may run something like
sort variables by name.
SPSS Reorder Variables - Final Note
In some cases, you may need to sort your variables in a structured manner that's more complex than covered by this tutorial. An example is sorting (many) variables according to subscripts in their variable names. The way to get such cases done efficiently is by using Python in SPSS.
THIS TUTORIAL HAS 22 COMMENTS:
By Harry on August 3rd, 2017
I have obtained data on 3 variables - Asians, Caucasians and South Asians. Each has a single value label (such as 1 = 'Asians'). I want to combine these into a single variable (Ethnicity) with value labels such as (1 = 'Asians', 2 = 'Caucasians etc). I thought I will COMPUTE a new variable and APPLY DICTIONARY but it doesn't work
By Ruben Geert van den Berg on August 3rd, 2017
Hi Harry!
Your situation is slightly tricky. The fastest option is something like
string etni (a25).do repeat #var = et1 et2 et3./* et1 to et3 are the old etni variables.if(#var = 1) etni = valuelabel(#var).
end repeat.
execute.
Optionally, AUTORECODE the final result and perhaps look up DO REPEAT.
Does that get you any further?
By Yvonne Van Allen on March 5th, 2018
add files file */keep id to fname q1 to q5 all.
execute.
BEST SYNTAX LEARNED TO DATE -
BEFORE THIS - I USED DIRECTORY COMMAND TO INSERT VARIABLE - THEN CREATED VARIABLES USING SYNTAX.
By Kristof Van Dessel on April 5th, 2018
Hey, I tried the syntax:
add files
/FILE obbo1234.sav
/keep d_r obbonr gp_stud ALL.
execute.
but keep getting:
>Error # 61 in column 7. Text: obbo1234.sav
>The filename is not valid.
>Execution of this command stops.
>Note # 5146
>There is no working file to restore. You must define a working file before
>proceeding with your analysis.
execute.
Could someone help me with that?
By Ruben Geert van den Berg on April 5th, 2018
Hi Kristof!
Part of the problem is that you should always use quotes around a file name as in
GET FILE "bla.sav".The*in my syntax is a dataset (not a data file) which is why I don't need quotes.But this tutorial addresses reordering variables in the active dataset. So first open it, then run the syntax.
Or: reorder your variables while opening it with
GET FILE 'bla.sav'/keep v1 to v5.Your syntax mixes up the 2 syntaxes.Ok, please try that and let me know if either option gets the job done for you, ok?