Quick Overview Contents
In SPSS, SELECT IF permanently removes
a selection of cases (rows) from your data.
- Example 1 - Selection for 1 Variable
- Example 2 - Selection for 2 Variables
- Example 3 - Selection for (Non) Missing Values
- Tip 1 - Inspect Selection Before Deletion
- Tip 2 - Use TEMPORARY
Summary
SELECT IF in SPSS basically means “delete all cases that don't satisfy one or more conditions”. Like so, select if(gender = 'female'). permanently deletes all cases whose gender is not female. Let's now walk through some real world examples using bank_clean.sav, partly shown below.
Example 1 - Selection for 1 Variable
Let's first delete all cases who don't have at least a Bachelor's degree. The syntax below:
- inspects the frequency distribution for education level;
- deletes unneeded cases;
- inspects the results.
set tnumbers both.
*Run minimal frequencies table.
frequencies educ.
*Select cases with a Bachelor's degree or higher. Delete all other cases.
select if(educ >= 4).
*Reinspect frequencies.
frequencies educ.
Result
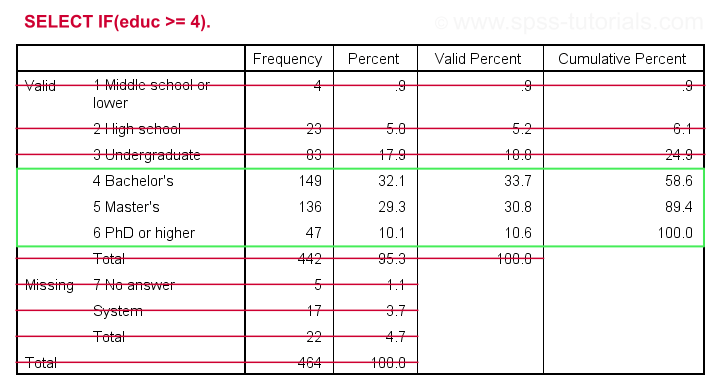
As we see, our data now only contain cases having a Bachelor's, Master's or PhD degree. Importantly, cases having
on education level have been removed from the data as well.
Example 2 - Selection for 2 Variables
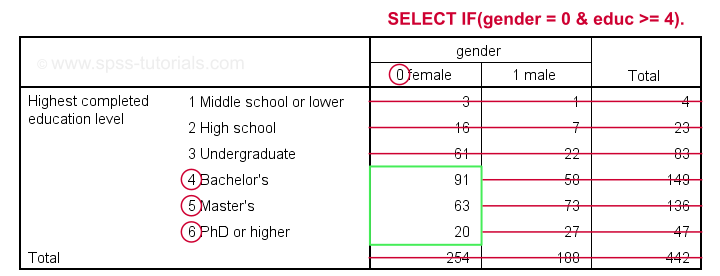
The syntax below selects cases based on gender and education level: we'll keep only female respondents having at least a Bachelor's degree in our data.
crosstabs educ by gender.
*Select females having a Bachelor's degree or higher.
select if(gender = 0 & educ >= 4).
*Reinspect contingency table.
crosstabs educ by gender.
Result
Example 3 - Selection for (Non) Missing Values
Selections based on (non) missing values are straightforward if you master SPSS Missing Values Functions. For example, the syntax below shows 2 options for deleting cases having fewer than 7 valid values on the last 10 variables (overall to q9).
select if(nvalid(overall to q9) >= 7)./*At least 7 valid values or at most 3 missings.
execute.
*Alternative way, exact same result.
select if(nmiss(overall to q9) < 4)./*Fewer than 4 missings or more than 6 valid values.
execute.
Tip 1 - Inspect Selection Before Deletion
Before deleting cases, I sometimes want to have a quick look at them. A good way for doing so is creating a FILTER variable. The syntax below shows the right way for doing so.
compute filt_1 = 0.
*Set filter variable to 1 for cases we want to keep in data.
if(nvalid(overall to q9) >= 7) filt_1 = 1.
*Move unselected cases to bottom of dataset.
sort cases by filt_1 (d).
*Scroll to bottom of dataset now. Note that cases 459 - 464 will be deleted because they have 0 on filt_1.
*If selection as desired, delete other cases.
select if(filt_1).
execute.
Quick note: select if(filt_1). is a shorthand for select if(filt_1 <> 0). and deletes cases having either a zero or a missing value on filt_1.
Result
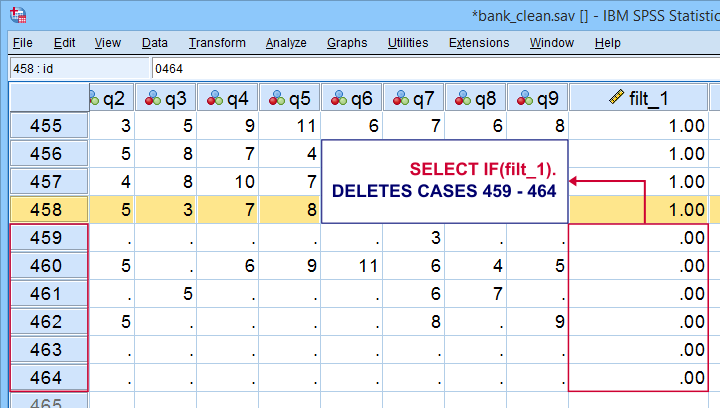 Cases that will be deleted are at the bottom of our data. We also readily see we'll have 458 cases left after doing so.
Cases that will be deleted are at the bottom of our data. We also readily see we'll have 458 cases left after doing so.
Tip 2 - Use TEMPORARY
A final tip I want to mention is combining SELECT IF with TEMPORARY. By doing so, SELECT IF only applies to the first procedure that follows it. For a quick example, compare the results of the first and second FREQUENCIES commands below.
temporary.
*Select only female cases.
select if(gender = 0).
*Any procedure now uses only female cases. This also reverses case selection.
frequencies gender educ.
*Rerunning frequencies now uses all cases in data again.
frequencies gender educ.
Final Notes
First off, parentheses around conditions in syntax are not required. Therefore, select if(gender = 0). can also be written as select if gender = 0. I used to think that shorter syntax is always better but I changed my mind over the years. Readability and clear structure are important too. I therefore use (and recommend) parentheses around conditions. This also goes for IF and DO IF.
Right, I guess that should do. Did I miss anything? Please let me know by throwing a comment below.
Thanks for reading!
THIS TUTORIAL HAS 29 COMMENTS:
By Nik on January 8th, 2019
Hi Ruben,
I have some problems for selecting duplicate cases. I hope you can help me.
I have two variables A and B, where A corresponds to interviewed people.
It's possible that in variable A codes repeat more than once.
I want to select all these cases where for every repeated case A, B values are the same.
For exemple
A B
1 : 10
1 : 15
2 : 1
3 : 7
4 : 8
4 : 8
I want to select values "4" from variable A, because in this case corresponding values from variable B are the same. Is it clear?
How could I do it?
Thank you!
By Ruben Geert van den Berg on January 8th, 2019
Hi Nicola!
Saying "b is the same for all records with the same a" means that the standard deviation of b within a is zero.
We can add it to the data with AGGREGATE and then use SELECT IF...
If I understand correctly, the syntax below should do what you're looking for.
Hope that helps!
*Set up test data.
data list free/a b.
begin data
1 10 1 15 2 1 3 7 4 8 4 8
end data.
*Add within-person SD to data.
aggregate outfile * mode addvariables
/break a
/sdb = sd(b).
*Select if b is constant (SD = 0) within person.
select if (sdb = 0).
execute.
By Nik on January 9th, 2019
Hi Ruben!
Firstly, thanky you for so quick answer! In this case I don't know if it's what I need...Maybe my explanation wasn't so clear.
I try again: when I use Data/Identify Duplicate Cases and I select a variable, SPSS creates a new variable PrimaryLast where there are primary cases and duplicate cases codified. My problem is that I've to make controls using either the primary and duplicate cases, so I want so select (probably using Select If) all those cases that repeat but NOT ONLY THE DUPLICATE, also the primary case.
For example
Variable A: 1 1 2 3 4 5 5
Actually I know how to select duplicate cases 1 and 5 but I don't know how to select also the primary cases. Finally I would like to select 1, 1, 5, 5.
I hope you can help me!
Thank you!
By Ruben Geert van den Berg on January 9th, 2019
Hi Nicola!
Sorry, I don't get what you're after. It sounds like something you'd do with LAG.
Take a look at the examples and see if any gets close.
If that doesn't help, send me some test data with the input variables and an indicator variable holding 1 for "keep" and 0 for "delete". Perhaps that explains the problem better than the written description.
Thanks!
By Esmee on June 18th, 2020
Hi Ruben,
In my data-set I want to remove all cases that have a score of 8 on a certain variable (which indicates a missing value).
However, when i enter 'select if ([variablename]~=8)', it also deselects all cases that have a score of 9 (which is the highest possible score). How can I delete ONLY those cases with score 8?
Thanks in advance,
Esmee