Working with string variables in SPSS is pretty straightforward if one masters some basic string functions. This tutorial will quickly walk you through the important ones.
SPSS Main String Functions
CHAR.SUBSTR(substring) - Extract character(s) from stringCONCAT(concatenate) - Combine stringsCHAR.INDEX- Find first occurrence of character(s) in stringCHAR.RINDEX(right index) - Find last occurrence of character(s) in string- REPLACE - Replace character(s) in string by different one(s)
CHAR.LENGTH- Return number of characters in string- LTRIM (left trim) - Remove leading spaces (or, rarely, other characters)
- RTRIM (right trim) - Remove right trailing spaces (or, rarely, other characters)
LOWER(lower case) - Convert all letters to lower caseUPCASE(upper case) - Convert all letters to upper case
SPSS Syntax Example
We asked respondents to type in their first name, surname prefix and last name. We'd like to combine these into full names and correct some irregularities such as incorrect casing and double spaces. For creating some test data, close all open datasets and run the syntax below.
*Create mini test dataset.
set unicode off.
data list free/s1 s2 s3 (3a20).
begin data
'ANNEKE' ' VAN DEN ' 'BERG' 'daan' '' 'balvert' 'a' '' 'b'
end data.
set unicode off.
data list free/s1 s2 s3 (3a20).
begin data
'ANNEKE' ' VAN DEN ' 'BERG' 'daan' '' 'balvert' 'a' '' 'b'
end data.
1. Correcting First Names
- One approach is to first correct each name component separately and then combine them.
- For the data at hand, first names should start with a capital and remaining letters should be in lower case.
- We'll break things up in small steps. We'll gradually combine these using substitution: using functions within functions.
- It's recommended you inspect the results carefully after running each step.
- Note there's separate tutorials on substrings and concatenate.
*1. Declare new string variables.
string n1 to n4 (a20).
*2. Extract first letter of first name.
compute n1 = char.substr(s1,1,1).
exe.
*3. Convert to upper case.
compute n1 = upcase(n1).
exe.
*4. Substitution: use substring function within upcase function.
compute n1 = upcase(char.substr(s1,1,1)).
exe.
*5. Extract remaining letters and convert to lower case.
compute n1 = lower(char.substr(s1,2)).
exe.
*6. Substitution: concatenate results from previous attempts.
compute n1 = concat(upcase(char.substr(s1,1,1)),lower(char.substr(s1,2))).
exe.
string n1 to n4 (a20).
*2. Extract first letter of first name.
compute n1 = char.substr(s1,1,1).
exe.
*3. Convert to upper case.
compute n1 = upcase(n1).
exe.
*4. Substitution: use substring function within upcase function.
compute n1 = upcase(char.substr(s1,1,1)).
exe.
*5. Extract remaining letters and convert to lower case.
compute n1 = lower(char.substr(s1,2)).
exe.
*6. Substitution: concatenate results from previous attempts.
compute n1 = concat(upcase(char.substr(s1,1,1)),lower(char.substr(s1,2))).
exe.
2. Correcting Surname Prefixes
- Since these are Dutch names, surname prefixes should be entirely in lower case.
- However, we'll first remove any leading spaces using the
LTRIMfunction. - Next we'll replace double by single spaces. For correcting longer sequences of spaces, see the second syntax example of SPSS LOOP Command.
*1. Remove leading spaces.
compute n2 = ltrim(s2).
exe.
*2. Substitution: remove leading spaces and convert to lower case.
compute n2 = lower(ltrim(s2)).
exe.
*3. Replace double spaces by single spaces.
compute n2 = replace(n2,' ',' ').
exe.
compute n2 = ltrim(s2).
exe.
*2. Substitution: remove leading spaces and convert to lower case.
compute n2 = lower(ltrim(s2)).
exe.
*3. Replace double spaces by single spaces.
compute n2 = replace(n2,' ',' ').
exe.
3. Combining First and Last Names
- For last names, the same rules hold as for first names: the first letter in upper case and remaining letters in lower case.
- Therefore, we can reuse the expression we wrote for the first names after some minor modifications.
- Now, combining first, middle and last names requires slightly more than a basic concatenation. This is because SPSS automatically right pads string values with spaces to match the length of the string variable.
- Therefore, concatenating 3 strings with length 20 results in a string with length 60. In case of insufficient variable width, only the first characters are shown. This is what happens in the example below (although it looks like the concatenation is not working).
- In Unicode mode
RTRIMis applied automatically. However, including it in the syntax anyway ensures that things will work properly regardless whether or not SPSS is in Unicode mode or not.
*1. Reuse capitalization syntax used for first name on last name.
compute n3 = concat(upcase(char.substr(s3,1,1)),lower(char.substr(s3,2))).
exe.
*2. If rtrim is omitted, concat doesn't seem to work.
compute n4 = concat(n1,n2,n3).
exe.
*3. Correct concatenation but spaces should be inserted.
compute n4 = concat(rtrim(n1),rtrim(n2),rtrim(n3)).
exe.
*4. Final concatenation.
compute n4 = concat(rtrim(n1),' ',rtrim(n2),' ',rtrim(n3)).
exe.
*5. Replace double spaces by single spaces.
compute n4 = replace(n4,' ',' ').
exe.
compute n3 = concat(upcase(char.substr(s3,1,1)),lower(char.substr(s3,2))).
exe.
*2. If rtrim is omitted, concat doesn't seem to work.
compute n4 = concat(n1,n2,n3).
exe.
*3. Correct concatenation but spaces should be inserted.
compute n4 = concat(rtrim(n1),rtrim(n2),rtrim(n3)).
exe.
*4. Final concatenation.
compute n4 = concat(rtrim(n1),' ',rtrim(n2),' ',rtrim(n3)).
exe.
*5. Replace double spaces by single spaces.
compute n4 = replace(n4,' ',' ').
exe.
4. Flag Single Letter Names
- Unfortunately, not all respondents filled out their real names. Many of such cases can't be detected from the data at hand but some suspicious patterns are easily identified.
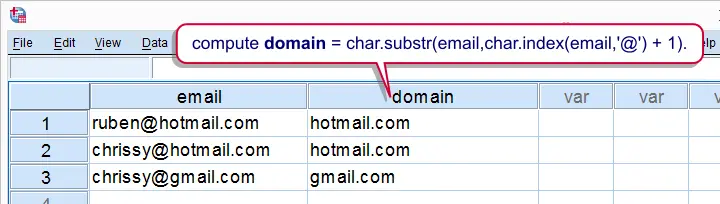
- One such pattern are very short (1 or 2 letter) first or last names. Since we have those separately in the data we can use
CHAR.LENGTHto flag these cases. - For combined names, the first name consists of all letters up to the first space. We can find it by using the
CHAR.INDEXfunction. - Reversely, the last name holds all letters after the last space which can be found by
CHAR.RINDEX. Subtracting the position of the last space from the length of the name returns the length of the last name. - For example, "Anneke van den Berg" are 19 letters. The last space is the 15th letter. Now 19 minus 15 returns 4 - which is indeed the length of "Berg".
*1. Find short first/last names from separate name components.
compute flag_1a = char.length(s1).
compute flag_1b = char.length(s3).
exe.
*2. Find short first/last names from combined names.
compute flag_2a = char.index(n4,' ') -1.
compute flag_2b = char.length(n4) - char.rindex(rtrim(n4),' ').
exe.
compute flag_1a = char.length(s1).
compute flag_1b = char.length(s3).
exe.
*2. Find short first/last names from combined names.
compute flag_2a = char.index(n4,' ') -1.
compute flag_2b = char.length(n4) - char.rindex(rtrim(n4),' ').
exe.
THIS TUTORIAL HAS 18 COMMENTS:
By Raina on June 8th, 2016
Hey Ruben!
I have a new question for you. To my knowledge I cannot do this with SPSS alone and I may have to use Python, but I'll let you tell me! Okay so... I have a file that lists clients and notes that staff members wrote about those clients. Each note is unique. I see the notes in the "back end" of our system. In front and behind those notes are HTML tags that indicate that the "front-end" staff members used to format their note text (bold, underline, etc.). A short example of the note a staff member might write looks like this (everything in double quotations): " Client is experiencing joint pain. " .. I want to look at the notes staff members wrote without the formatting code before and after it. Another way of saying it is that I want to delete everything between the delimiters "" and keep only "Client is experiencing joint pain." Do you have any suggestions? I've tried to write some python code within SPSS, but I am not sure where i am going wrong ("note_new" is supposed to be the new variable without the formatting code that just contains the text i want):
begin program python.
import spss,spssdata
import re
note_new = 'keep client note '
re.sub('', '', note_new)
'keep client note '
end program.
By Ruben Geert van den Berg on June 9th, 2016
Hi Raina!
If I understand correctly, you've one or many string variables from which you'd like to delete everything between double quotes? You can do so with LOOP, char.index and char.substr. No Python needed for that.
But what if the double quote occurs 1, 3 or 4 times in the string? Then what's supposed to happen? Or doesn't that apply to your data?
By Raina Moyer on June 10th, 2016
Hi Ruben! For some reason parts of my original question got deleted before I submitted it to you. Sorry for the confusion! Let me try again, more simply:
**What I see is just one string variable and an example looks like this:
Client is experiencing joint pain.
**I want to delete everything between all the delimiters and ONLY keep the following text (not in any quotes):
Client is experiencing joint pain.
**I actually tried using loop with the string transformation functions before I tried python, but as you indicated, it only takes out the first instance of things between the delimiters. I tried writing that python code to delete the 2nd, 3rd, etc time the text between the delimiters occurred in the note field.
By Ruben Geert van den Berg on June 11th, 2016
Hi Raina!
I think some part of your comment got deleted again, perhaps due to HTML tags in it? Could you please try and send me the original text by email? And if that doesn't work, take a screenshot of it and send that by email? It's a nice question and it really bothers me it isn't getting through correctly.
By Raina (Moyer) Palta on June 14th, 2016
Hey Ruben!
Yes, something did get deleted... it was everything between these "<" brackets that look like HTML tags. The better news is that I figured out the solution to my problem. I learned how to use the VECTOR command with a do-if/end-if structure within a loop/end-loop..My problem stemmed from the fact that the HTML tags were all in the notes (front, middle, end)... I was using notes that were about ~7000 characters long and combining a lot of notes, so that made it more complicated. It took up to 85 loops to get the HTML tags removed! Happy to share my code; its quite long and there may be a quicker way:
Note: I use SPSS in code page mode (aka UNICODE is OFF).
string notestr(A8000).
compute notestr = ltrim(FOURTY_NOTE).
execute.
compute LTposition = char.index(notestr,'').
- compute notefinal = ltrim(char.substr(notestr,(GTposition+1))).
- compute notestr = notefinal.
- compute LTposition = char.index(notestr,'').
execute.
vector note(85,a8000).
set mxloops 85.
loop #i = 1 to 84.
do if LTposition 0 and GTposition 0.
- compute notefinal = ' '.
- compute note(#i) = char.substr(notestr,1,(LTposition-1)).
- compute notestr = char.substr(notestr,GTposition+1).
- compute LTposition = char.index(notestr,'').
- compute note(85) = concat(notestr,' ').
end if.
end loop.
compute LTposition85 = char.index(note85,'<').
execute.
if LTposition85=1 note85=' '.
execute.
vector V=note2 to note85.
set mxloops 85.
loop #j = 2 to 84.
- compute notefinal = concat( rtrim(ltrim(notefinal)), ' ', rtrim(ltrim(V(#j))) ).
end loop.
sort cases note85 (d).
compute notefinal = concat( rtrim(ltrim(notefinal)), ' ', rtrim(ltrim(note86)) ).
execute.
E-mailed as well.