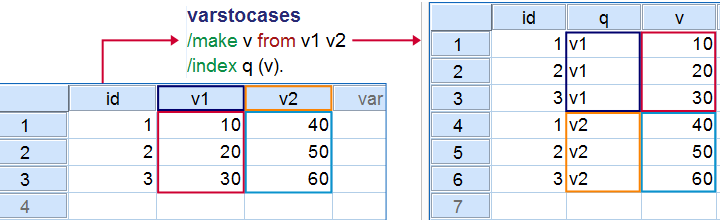
SPSS VARSTOCASES is short for “variables to cases”. It restructures data by stacking variables on top of each other as illustrated by the figure above. You can try this simple example for yourself by downloading and opening sav_data018 and running the syntax below on it.
SPSS VARSTOCASES Example 1
varstocases
/make v from v1 v2
/index q (v).
SPSS VARSTOCASES - Why?
One good reason for using VARSTOCASES is that many SPSS graphs can only be generated after stacking the relevant variables on top of each other. On top of that, VARSTOCASES also facilitates generating some tables. For example, let's take a look at some of the data in freelancers.sav.
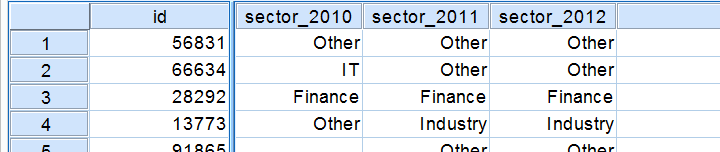
We may want to compare the sectors our respondents have been working in over years as in the table below.
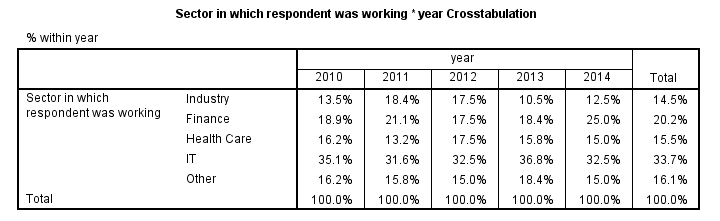
Makes sense, right? Now, one way for creating this table is CTABLES (custom tables) but this requires a (paid) add-on module. Second, TABLES will do the trick but it's available only in (challenging) syntax and no longer documented.
The third option is VARSTOCASES followed by CROSSTABS as demonstrated below. Note that VARSTOCASES results in an incorrect variable label so we correct that in step 2. We'll discuss this problem a bit later on.
SPSS VARSTOCASES Example 2
varstocases
/make sector from sector_2010 to sector_2014
/index year(sector).
*2. Correct variable label.
variable labels sector "Sector in which respondent was working".
*3. Extract year from string.
compute year = char.substr(year,index(year,'_') + 1).
execute.
*4. Generate table.
crosstabs sector by year/cells column.
SPSS VARSTOCASES - Creating Multiple Variables
Our first two examples created one variable holding the original values and a second (index) variable holding the original variable names. In some cases, however, you may want to restructure multiple sets of variables in one go. For instance, let's consider sav_data016, holding typical reaction time data.
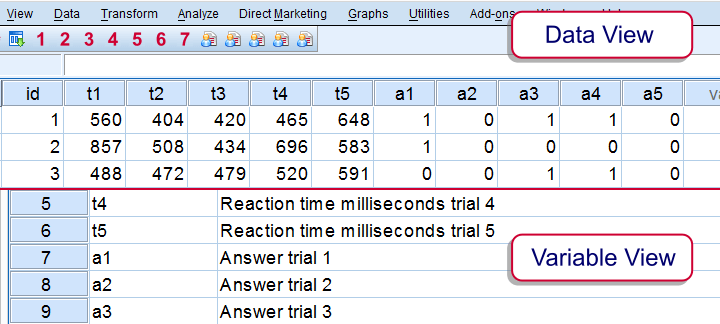
Apparently, respondents took 5 trials, each resulting in an answer and a reaction time. So do wrong answers have shorter or longer average reaction times? One way to figure out is using the VARSTOCASES syntax below, perhaps followed by MEANS.
SPSS VARSTOCASES Example 3
varstocases
/make t from t1 to t5
/make a from a1 to a5
/index trial.
Result

SPSS VARSTOCASES - Wrong Results
In our second example, we placed two variables on top of each other in one new variable. Both input variables had a variable label but the (single) output variable can have only one variable label. SPSS “solves” the problem by using the first variable label it encounters. In most cases, this will be incorrect but we'll readily see the problem.
The real problem with VARSTOCASES is that the same principle holds for value labels. This may result in nonsensical results. We'll now demonstrate this on sav_data017, part of which are shown below.

We first run basic FREQUENCIES. Note that both questions basically indicate that politicians are not very popular with our respondents.
set tnumbers both.
*2. Frequency tables.
frequencies v1 v2.
Result

Importantly, these tables also show that our two variables have inconsistent value labels. We now run VARSTOCASES and replicate both frequency tables with a single contingency table.
SPSS VARSTOCASES Example 4
varstocases
/make v from v1 v2
/index question(v).
*2. Remove incorrect variable label.
variable labels v ''.
*3. Note that result is not correct.
crosstabs v by question/cells columns.
Result

Note that VARSTOCASES has applied the value labels of v1 to the values of v1 and v2, resulting in misleading results. Even more disturbing, SPSS didn't throw any error or warning that things were going wrong at some point.
Believe it or not but this is not a bug. VARSTOCASES is supposed to work like this and this behavior is described in the CSR. We wonder, however, how many SPSS users are aware that this may happen. And even those who are aware have no efficient way for circumventing it as SPSS completely lacks any dictionary consistency check.
On a personal note, we feel that VARSTOCASES should perform such a check by default and at least issue a warning if things do go wrong. This suggestion goes for ADD FILES too, which shows similar problematic behavior which is even harder to avoid.
THIS TUTORIAL HAS 9 COMMENTS:
By Ruben Geert van den Berg on May 8th, 2016
Hi Jon!
I didn't know you could AUTORECODE numeric variables for creating a template. However, I tried it and the result was neither as expected nor as desired. A tiny syntax example that illustrates the problem is SPSS AUTORECODE - Save and Apply Template Going Bad.
By Jon Peck on May 8th, 2016
Sorry, that is not at all how AUTORECODE is supposed to work. You can open the generated likert.sat file to see the mapping defined by the command. (It has extension sat but is actually in sav file format.) You can, in fact, create your own mapping there. In your example, the sat file defines the mapping for the values it found (1-6), but none of those values occur in the second variable, so the template has no effect.
What I had in mind was that you establish the mapping for the same set of values in the template and then just use that in the future.
By Ruben Geert van den Berg on May 8th, 2016
I see. I thought the syntax example was you were hinting at when you wrote "You take a variable that is properly coded and run AUTORECODE on it saving a template."
Perhaps you're better off by recycling a plain syntax RECODE and VALUE LABELS command, especially since both'll take many variables if desired. I actually use a collection of syntax/chart template snippets that I often use in a GoogleDoc, which works really well for me.
By Jon Peck on May 8th, 2016
All you are really doing in this case is providing a convent way to apply standard sorts of recoded. But if you enrich your metadata with attributes like Likert, you could have Python code use that to do the recode automatically. In fact the SPSSINC SELECT VARIABLES extension command could select all of your Variables with a Likert attribute and make a macro listing them.