- Overview Transformations
- Normalizing - What and Why?
- Normalizing Negative/Zero Values
- Test Data
- Descriptives after Transformations
- Conclusion
Overview Transformations
| TRANSFORMATION | USE IF | LIMITATIONS | SPSS EXAMPLES |
|---|---|---|---|
| Square/Cube Root | Variable shows positive skewness Residuals show positive heteroscedasticity Variable contains frequency counts | Square root only applies to positive values | compute newvar = sqrt(oldvar). compute newvar = oldvar**(1/3). |
| Logarithmic | Distribution is positively skewed | Ln and log10 only apply to positive values | compute newvar = ln(oldvar). compute newvar = lg10(oldvar). |
| Power | Distribution is negatively skewed | (None) | compute newvar = oldvar**3. |
| Inverse | Variable has platykurtic distribution | Can't handle zeroes | compute newvar = 1 / oldvar. |
| Hyperbolic Arcsine | Distribution is positively skewed | (None) | compute newvar = ln(oldvar + sqrt(oldvar**2 + 1)). |
| Arcsine | Variable contains proportions | Can't handle absolute values > 1 | compute newvar = arsin(oldvar). |
Normalizing - What and Why?
“Normalizing” means transforming a variable in order to
make it more normally distributed.
Many statistical procedures require a normality assumption: variables must be normally distributed in some population. Some options for evaluating if this holds are
- inspecting histograms;
- inspecting if skewness and (excess) kurtosis are close to zero;
- running a Shapiro-Wilk test and/or a Kolmogorov-Smirnov test.
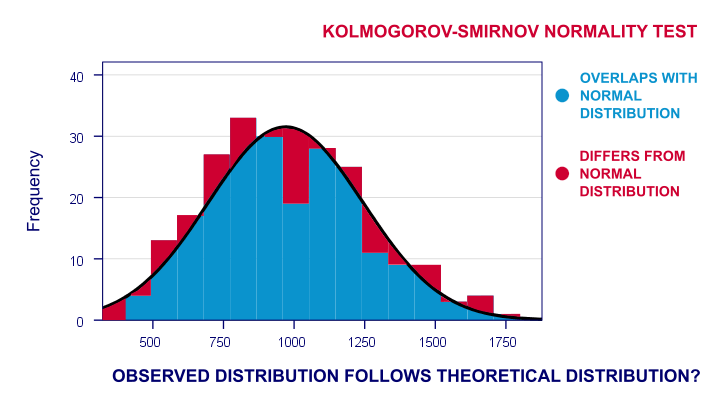
For reasonable sample sizes (say, N ≥ 25), violating the normality assumption is often no problem: due to the central limit theorem, many statistical tests still produce accurate results in this case. So why would you normalize any variables in the first place? First off, some statistics -notably means, standard deviations and correlations- have been argued to be technically correct but still somewhat misleading for highly non-normal variables.
Second, we also encounter normalizing transformations in multiple regression analysis for
- meeting the assumption of normally distributed regression residuals;
- reducing heteroscedasticity and;
- reducing curvilinearity between the dependent variable and one or many predictors.
Normalizing Negative/Zero Values
Some transformations in our overview don't apply to negative and/or zero values. If such values are present in your data, you've 2 main options:
- transform only non-negative and/or non-zero values;
- add a constant to all values such that their minimum is 0, 1 or some other positive value.
The first option may result in many missing data points and may thus seriously bias your results. Alternatively, adding a constant that adjusts a variable's minimum to 1 is done with
$$Pos_x = Var_x - Min_x + 1$$
This may look like a nice solution but keep in mind that a minimum of 1 is completely arbitrary: you could just as well choose, 0.1, 10, 25 or any other positive number. And that's a real problem because the constant you choose may affect the shape of a variable's distribution after some normalizing transformation. This inevitably induces some arbitrariness into the normalized variables that you'll eventually analyze and report.
Test Data
We tried out all transformations in our overview on 2 variables with N = 1,000:
- var01 has strong negative skewness and runs from -1,000 to +1,000;
- var02 has strong positive skewness and also runs from -1,000 to +1,000;
These data are available from this Googlesheet (read-only), partly shown below.
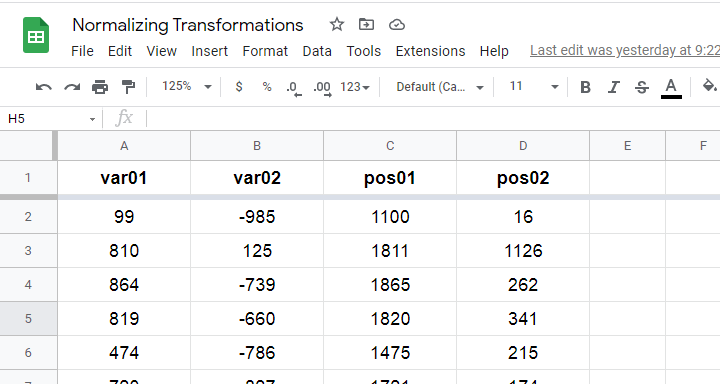
SPSS users may download the exact same data as normalizing-transformations.sav.
Since some transformations don't apply to negative and/or zero values, we “positified” both variables: we added a constant to them such that their minima were both 1, resulting in pos01 and pos02.
Although some transformations could be applied to the original variables, the “normalizing” effects looked very disappointing. We therefore decided to limit this discussion to only our positified variables.
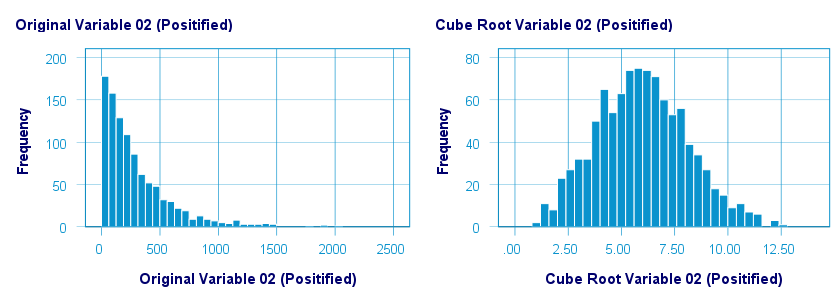
Square/Cube Root Transformation
A cube root transformation did a great job in normalizing our positively skewed variable as shown below.
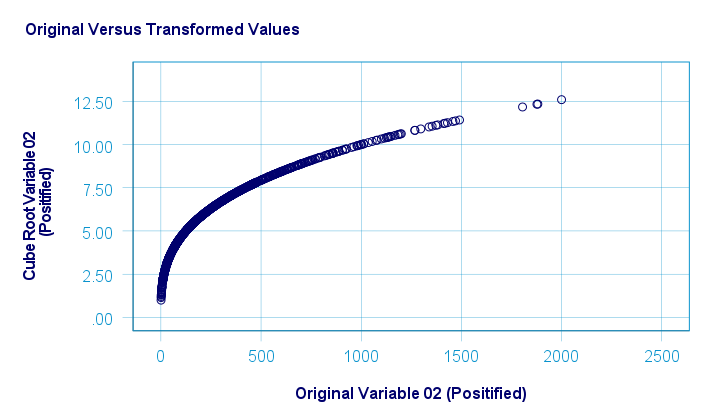
The scatterplot below shows the original versus transformed values.
SPSS refuses to compute cube roots for negative numbers. The syntax below, however, includes a simple workaround for this problem.
compute curt01 = pos01**(1/3).
compute curt02 = pos02**(1/3).
*NOTE: IF VARIABLE MAY CONTAIN NEGATIVE VALUES, USE.
*if(pos01 >= 0) curt01 = pos01**(1/3).
*if(pos01 < 0) curt01 = -abs(pos01)**(1/3).
*HISTOGRAMS.
frequencies curt01 curt02
/format notable
/histogram.
*SCATTERPLOTS.
graph/scatter pos01 with curt01.
graph/scatter pos02 with curt02.
Logarithmic Transformation
A base 10 logarithmic transformation did a decent job in normalizing var02 but not var01. Some results are shown below.
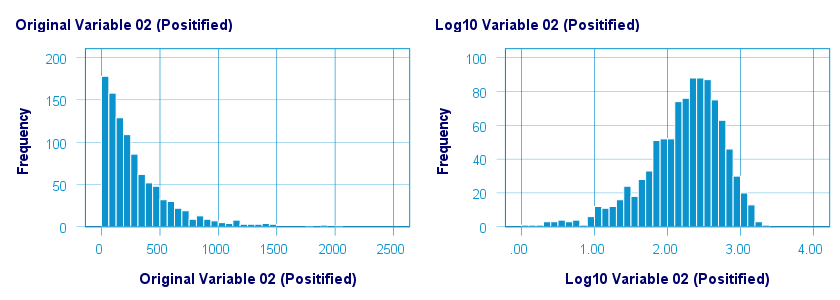
The scatterplot below visualizes the original versus transformed values.
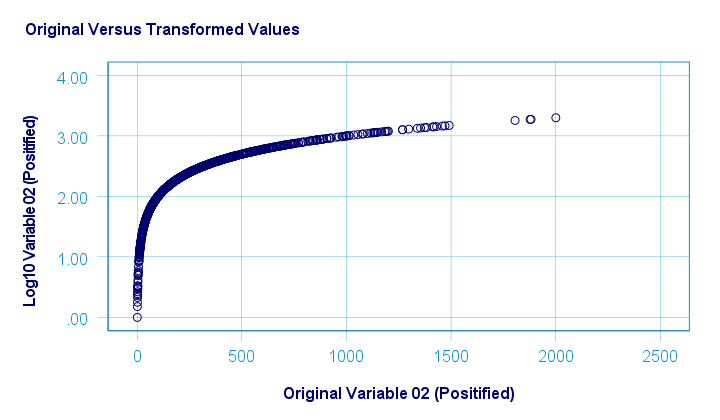
SPSS users can replicate these results from the syntax below.
compute log01 = lg10(pos01).
compute log02 = lg10(pos02).
*HISTOGRAMS.
frequencies log01 log02
/format notable
/histogram.
*SCATTERPLOTS.
graph/scatter pos01 with log01.
graph/scatter pos02 with log02.
Power Transformation
A third power (or cube) transformation was one of the few transformations that had some normalizing effect on our left skewed variable as shown below.
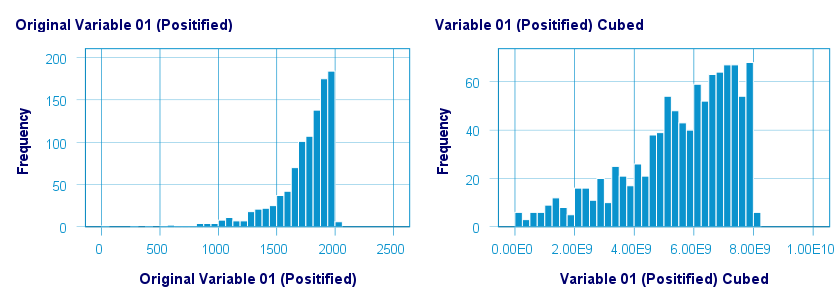
The scatterplot below shows the original versus transformed values for this transformation.
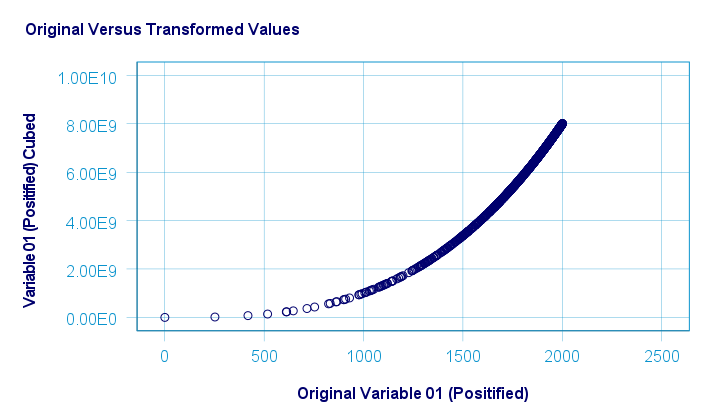
These results can be replicated from the syntax below.
compute cub01 = pos01**3.
compute cub02 = pos02**3.
*HISTOGRAMS.
frequencies cub01 cub02
/format notable
/histogram.
*SCATTERS.
graph/scatter pos01 with cub01.
graph/scatter pos02 with cub02.
Inverse Transformation
The inverse transformation did a disastrous job with regard to normalizing both variables. The histograms below visualize the distribution for pos02 before and after the transformation.
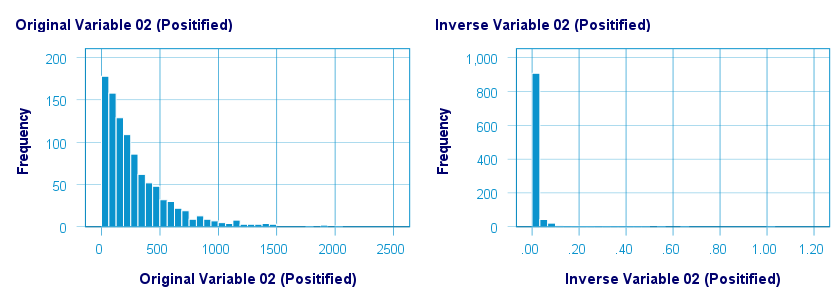
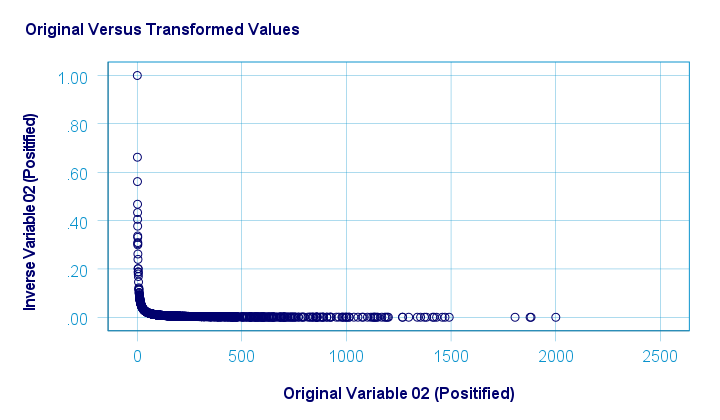
The scatterplot below shows the original versus transformed values. The reason for the extreme pattern in this chart is setting an arbitrary minimum of 1 for this variable as discussed under normalizing negative values.
SPSS users can use the syntax below for replicating these results.
compute inv01 = 1 / pos01.
compute inv02 = 1 / pos02.
*NOTE: IF VARIABLE MAY CONTAIN ZEROES, USE.
*if(pos01 <> 0) inv01 = 1 / pos01.
*HISTOGRAMS.
frequencies inv01 inv02
/format notable
/histogram.
*SCATTERPLOTS.
graph/scatter pos01 with inv01.
graph/scatter pos02 with inv02.
Hyperbolic Arcsine Transformation
As shown below, the hyperbolic arcsine transformation had a reasonably normalizing effect on var02 but not var01.
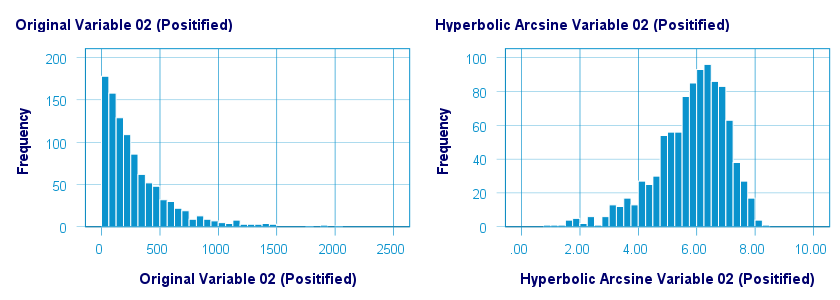
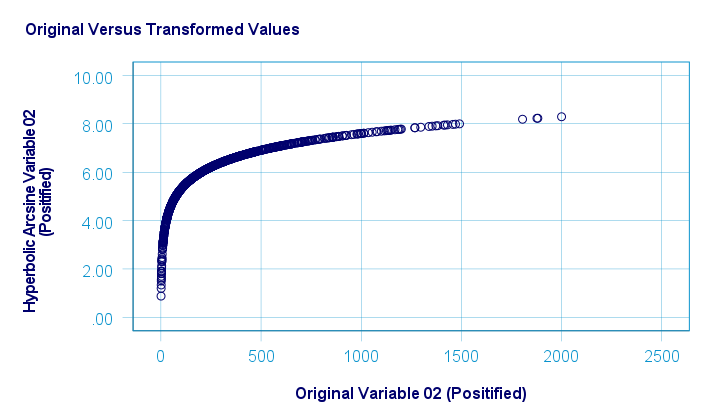
The scatterplot below plots the original versus transformed values.
In Excel and Googlesheets, the hyperbolic arcsine is computed from =ASINH(...) There's no such function in SPSS but a simple workaround is using
$$Asinh_x = ln(Var_x + \sqrt{Var_x^2 + 1})$$
The syntax below does just that.
compute asinh01 = ln(pos01 + sqrt(pos01**2 + 1)).
compute asinh02 = ln(pos02 + sqrt(pos02**2 + 1)).
*HISTOGRAMS.
frequencies asinh01 asinh02
/format notable
/histogram.
*SCATTERS.
graph/scatter pos01 with asinh01.
graph/scatter pos02 with asinh02.
Arcsine Transformation
Before applying the arcsine transformation, we first rescaled both variables to a range of [-1, +1]. After doing so, the arcsine transformation had a slightly normalizing effect on both variables. The figure below shows the result for var01.
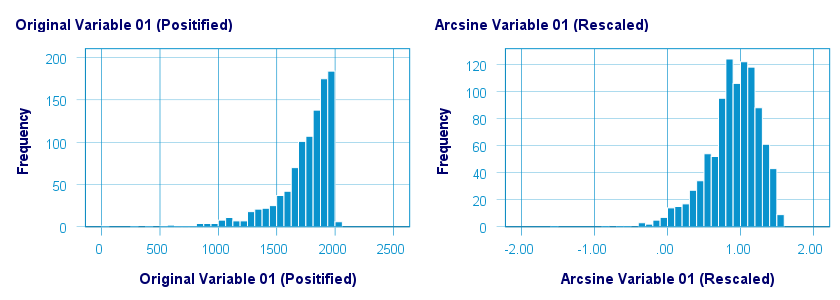
The original versus transformed values are visualized in the scatterplot below.
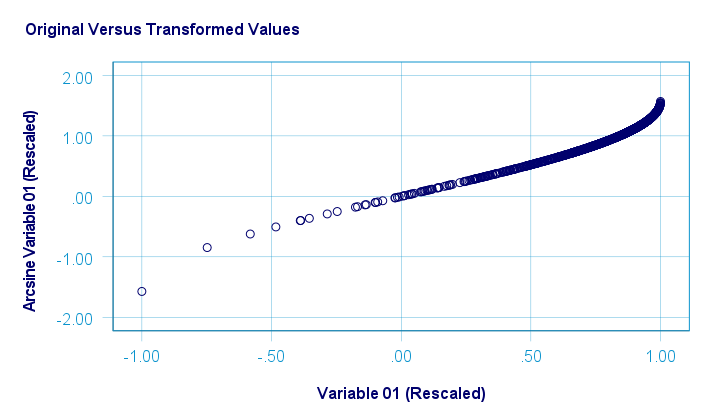
The rescaling of both variables as well as the actual transformation were done with the SPSS syntax below.
aggregate outfile * mode addvariables
/min01 min02 = min(var01 var02)
/max01 max02 = max(var01 var02).
*RESCALE VARIABLES TO [-1, +1] .
compute trans01 = (var01 - min01)/(max01 - min01)*2 - 1.
compute trans02 = (var02 - min01)/(max01 - min01)*2 - 1.
*ARCSINE TRANSFORMATION.
compute asin01 = arsin(trans01).
compute asin02 = arsin(trans02).
*HISTOGRAMS.
frequencies asin01 asin02
/format notable
/histogram.
*SCATTERS.
graph/scatter trans01 with asin01.
graph/scatter trans02 with asin02.
Descriptives after Transformations
The figure below summarizes some basic descriptive statistics for our original variables before and after all transformations. The entire table is available from this Googlesheet (read-only).
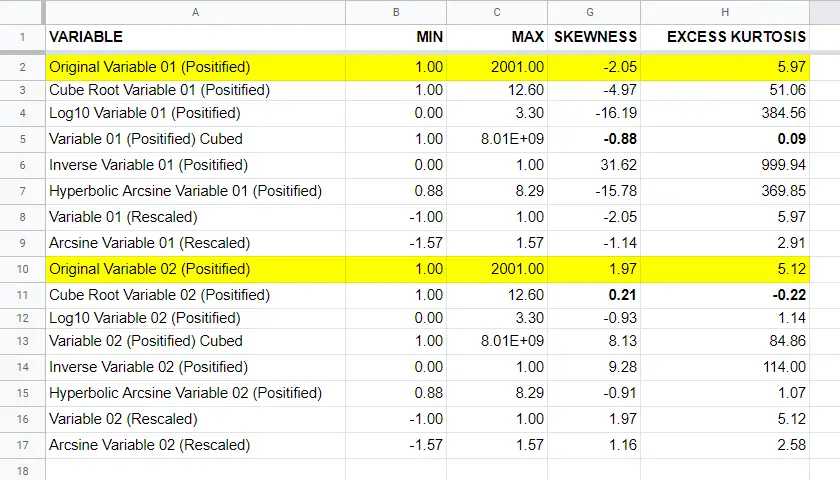
Conclusion
If we only judge by the skewness and kurtosis after each transformation, then for our 2 test variables
- the third power transformation had the strongest normalizing effect on our left skewed variable and
- the cube root transformation worked best for our right skewed variable.
I should add that none of the transformations did a really good job for our left skewed variable, though.
Obviously, these conclusions are based on only 2 test variables. To what extent they generalize to a wider range of data is unclear. But at least we've some idea now.
If you've any remarks or suggestions, please throw us a quick comment below.
Thanks for reading.
THIS TUTORIAL HAS 15 COMMENTS:
By Jon Peck on February 21st, 2022
This is a nice study, but it omits what might be the best normalizing transformation, which is automatic. That is the Box-Cox transformation, which is a combination of a log and power transformation. It has one parameter, lambda, that controls the shape. In SPSS Statistics, this is available in the ADP procedure (Transform > Prepare Data for Modeling > interactive or automatic). The procedure finds the optimal value of lambda by maximizing a likelihood function. Details are in the Algorithms manual.
Another point: Besides the normality tests mentioned, the Anderson-Darling test, which is available in the Simulation procedure can be a good choice. It is more sensitive to the tails of the distribution, which is important in some situations.
Finally, on the cube root, the computation is done by use of logarithms, which allows for handling fractional powers, but it precludes negative values.
p.s., The Box-Cox transformation was invented by George Box and the late David Cox, who were said to feel compelled by Gilbert & Sullivan fans to write a paper together.
By Ruben Geert van den Berg on February 22nd, 2022
Hi Jon, thanks for your feedback!
Sadly, none of my text books mentions the Box-Cox transformation. I'll look it up and I might add it to the tutorial with its first update.
The point regarding cube roots is that Excel and Googlesheets compute it without any hesitations for negative numbers. Some of my students thought it was mathematically impossible because SPSS refused to do the same... But a simple workaround with IF and ABS() is fine as long as you're aware of it...
By Jon Peck on February 22nd, 2022
I am surprised that Box-Cox is not mentioned. Sometimes it is referenced in a Tukey ladder of powers discussion.
And, in Excel, try this=-3.14159^(1.001/3)
By Ruben Geert van den Berg on February 23rd, 2022
Funny, that neither works in Excel nor SPSS. However, -(abs(...))... does work in both packages but I'm not sure if that's mathematically correct in this case.
Does any of your literature include a thorough discussion of Box-Cox?
My "bible" is often Rebecca Warner but she only mentions Box's M test for the equality of population covariance matrices in MANOVA...
By Jon Peck on February 23rd, 2022
I suggest the original Box-Cox article that you can get here.
https://www.ime.usp.br/~abe/lista/pdfQWaCMboK68.pdf
It may be more than you want to know. :-)
As for the expression
-3.14159 ** ...
it depends on the operator precedence rules of the engine. If the minus sign has higher precedence than exponentiation, then the result may be a complex number. Otherwise, the sign is applied to the result of the exponentiation. E.g.,
(-3.14159)**(1/2) gives
(1.0853145092106557e-16+1.7724531023414978j)
if the system supports complex numbers and
3.14159 ** (1/2) gives
-1.7724531023414978
But if the term being exponentiated happens to be a variable with a negative value, then you don't have control over the operator order.
In Statistics, -3.14159 is treated as a constant, which is what you would get if it is a variable, so you would produce a complex number, which is not supported in Statistics.