Also see Pearson Correlations - Quick Introduction.
SPSS CORRELATIONS creates tables with Pearson correlations and their underlying N’s and p-values. For Spearman rank correlations and Kendall’s tau, use NONPAR-CORR. Both commands can be pasted from
![]()
![]() .
.
This tutorial quickly walks through the main options. We'll use freelancers.sav throughout and we encourage you to download it and follow along with the examples.
User Missing Values
Before running any correlations, we'll first specify all values of one million dollars or more as user missing values for income_2010 through income_2014.Inspecting their histograms (also see FREQUENCIES) shows that this is necessary indeed; some extreme values are present in these variables and failing to detect them will have a huge impact on our correlations. We'll do so by running the following line of syntax: missing values income_2010 to income_2014 (1e6 thru hi). Note that “1e6” is a shorthand for a 1 with 6 zeroes, hence one million.
SPSS CORRELATIONS - Basic Use
The syntax below shows the simplest way to run a standard correlation matrix. Note that due to the table structure, all correlations between different variables are shown twice.
By default, SPSS uses pairwise deletion of missing values here; each correlation (between two variables) uses all cases having valid values these two variables. This is why N varies from 38 through 40 in the screenshot below.
correlations income_2010 to income_2014.
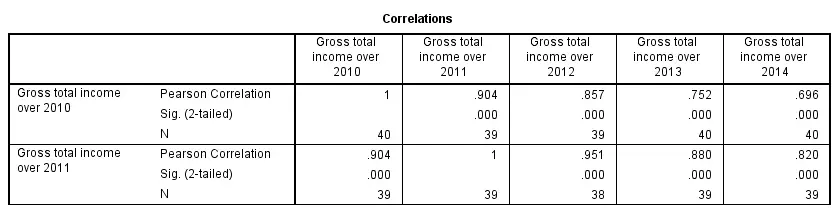
Keep in mind here that p-values are always shown, regardless of whether their underlying statistical assumptions are met or not. Oddly, SPSS CORRELATIONS doesn't offer any way to suppress them. However, SPSS Correlations in APA Format offers a super easy tool for doing so anyway.
SPSS CORRELATIONS - WITH Keyword
By default, SPSS CORRELATIONS produces full correlation matrices. A little known trick to avoid this is using a WITH clause as demonstrated below. The resulting table is shown in the following screenshot.
correlations income_2010 with income_2011 to income_2014.

SPSS CORRELATIONS - MISSING Subcommand
Instead of the aforementioned pairwise deletion of missing values, listwise deletion is accomplished by specifying it in a MISSING subcommand.An alternative here is identifying cases with missing values by using NMISS. Next, use FILTER to exclude them from the analysis. Listwise deletion doesn't actually delete anything but excludes from analysis all cases having one or more missing values on any of the variables involved.
Keep in mind that listwise deletion may seriously reduce your sample size if many variables and missing values are involved. Note in the next screenshot that the table structure is slightly altered when listwise deletion is used.
correlations income_2010 to income_2014
/missing listwise.

SPSS CORRELATIONS - PRINT Subcommand
By default, SPSS CORRELATIONS shows two-sided p-values. Although frowned upon by many statisticians, one-sided p-values are obtained by specifying ONETAIL on a PRINT subcommand as shown below.
Statistically significant correlations are flagged by specifying NOSIG (no, not SIG) on a PRINT subcommand.
correlations income_2010 with income_2011 to income_2014
/print nosig onetail.
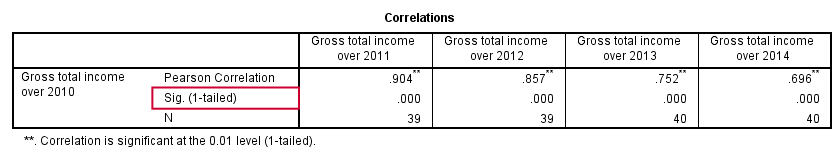
SPSS CORRELATIONS - Notes
More options for SPSS CORRELATIONS are described in the command syntax reference. This tutorial deliberately skipped some of them such as inclusion of user missing values and capturing correlation matrices with the MATRIX subcommand. We did so due to doubts regarding their usefulness.
Thanks for reading!
THIS TUTORIAL HAS 7 COMMENTS:
By Herbert Blumberg on October 27th, 2023
Useful summary tutorial! thank you.
By Phil on February 15th, 2024
thank you! only tutorial ive found that explains the WITH clause