- Inspect Frequency Table
- Extract Leading Digits
- Inspect Which Values Couldn't be Converted
- Inspect Final Results
Recently, one of our clients used a text field for asking his respondents’ ages. The resulting age variable is in age-in-string.sav, partly shown below.
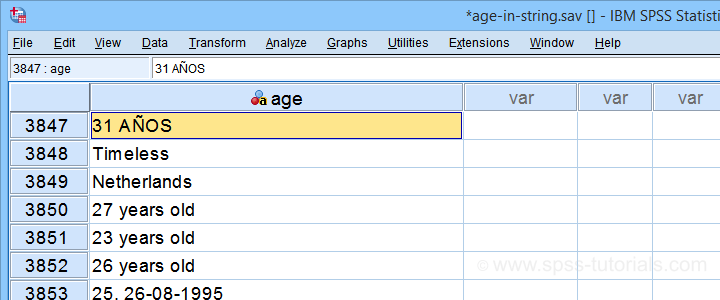
I hope you realize that this looks nasty:
- age is a string variable so we can't compute its mean, standard deviation or any other statistic;
- we can't readily convert age into a numeric variable because it contains more than just numbers;
- a simple text replacement won't remove all such undesired characters.
For adding injury to insult, the data contain 3,895 cases so doing things manually is not feasible. However, we'll quickly fix things anyway.
Inspect Frequency Table
Let's first see which problematic values we're dealing with anyway. So let's run a basic frequency table with the syntax below.
frequencies age
/format dfreq.
Result
If we scroll down our table a bit, we'll see some problematic values as shown below.
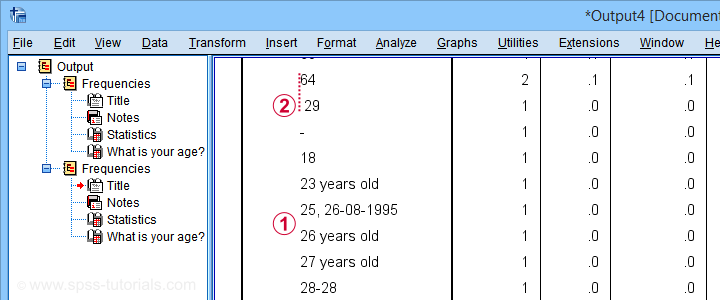
This table shows us 2 important things:
 most values that can be corrected start off with 2 digits;
most values that can be corrected start off with 2 digits;
 at least one value is preceded by a leading space.
at least one value is preceded by a leading space.
Let's first remove any leading spaces. We'll simply do so by running compute age = ltrim(age).
Extract Leading Digits
We'll now extract any leading digits from our string variable with the syntax below.
string nage (a3).
*Loop over characters in age and pass into nage if they are digits.
loop #ind = 1 to char.length(age).
do if(char.index('0123456789',char.substr(age,#ind,1)) > 0).
compute nage = concat(rtrim(nage),char.substr(age,#ind,1)).
else.
break.
end if.
end loop.
execute.
So what we very basically do here is
- we create a new string variable;
- we LOOP through all characters in age;
- we evaluate if each character is a digit: char.index returns 0 if the character can't be found in '0123456789'.
- if the character is a digit (DO IF), we'll add it to the end of our new string variable;
- if the character is not a digit (ELSE), BREAK ends the loop for that particular respondent.
This last condition is needed for values such as “55 and will become 56 on 3/9” We need to make sure that no digits after “55” are added to our new variable. Otherwise, we'll end up with “555639” -an age perhaps only plausible for Fred Flintstone.
Inspect Which Values Couldn't be Converted
Let's now inspect which original age values could not be converted. We'll rerun our frequency distribution but we'll restrict it to respondents whose new age value is still empty.
temporary.
select if (nage = '').
*Check which age values weren't converted yet.
frequencies age
/format dfreq.
Result
Surprisingly, a quick scroll down our table shows that we can reasonably convert only a single unconverted age value: “Will become 56 on the 3rd of September:-)”
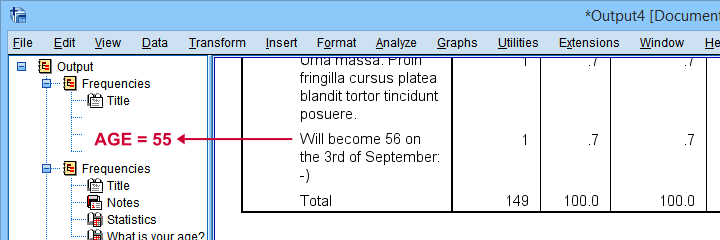
It is probably safe to infer from this statement that this person was 55 years old at questionnaire completion. We'll set his age to 55 with a simple IF command. We'll then run a quick final check.
if(char.index(age,'Will become 56') > 0) nage = '55'.
*Recheck which age values weren't converted yet.
temporary.
select if (nage = '').
frequencies age
/format dfreq.
Final Frequency Table
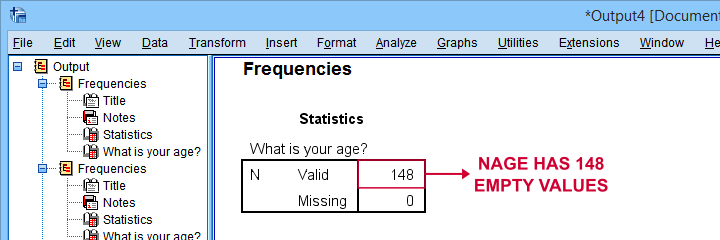
As shown below, our minimal corrections resulted in a mere 148 (out of 3,895) unconverted ages. A quick scroll down our table shows that no further conversions are possible.
We'll now convert our new age variable into numeric with ALTER TYPE and inspect the result.
alter type nage(f3).
*Check age distribution.
frequencies nage
/histogram.
*Exclude nage = 99 from all analyses and/or editing.
missing values nage (99).
Inspect Final Results
First off, note that our final age variable has N = 148 missing values -just as expected. It is important to check this because ALTER TYPE may result in missing values without throwing any error or warning.
Next, a histogram over our final age values is shown below.
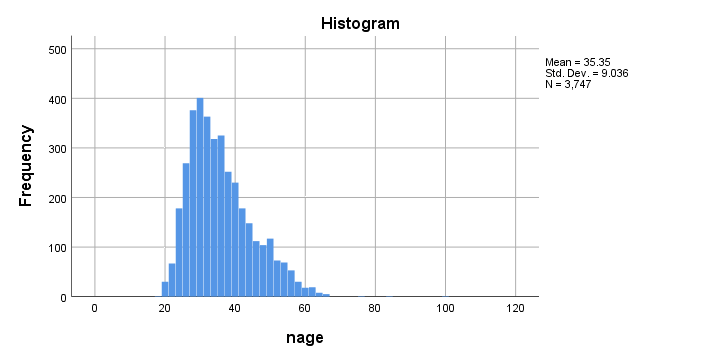
Although the age distribution looks plausible, the x-axis runs up to 120 years. SPSS often applies a 20% margin on both sides so this may indicate an age around 100 years.
Closer inspection shows that somebody reported an age of 99 years. As we think that's not plausible for the current study, we set it as a user missing value.
Done.
Thanks for reading!
THIS TUTORIAL HAS 11 COMMENTS:
By Jon K Peck on August 29th, 2023
The SPSS product managers over the years prioritize the scarce development resources taking into account user requests and their goals for a release. There are always many more things they and the team would like to do, so many good things just don't make the cut. I had the freedom for many years to just do things via Python, R. and extensions based on what I thought was needed and what I heard from users. I could contribute to general priorities and designs, but it was and still is much quicker to build things through Python and R extensions when that is possible. The three shrinkage estimators in V29 are all implemented in Python, so development can be done that way by the regular staff..
Over time, different product managers have made different choices over what extensions to include in the regular installation, but there is a tradeoff between adding too much complexity to the menus and exposing added functionality. On top of that, R-based extensions were an issue with IBM Legal for some time due to the GNU licensing requirement. I've been surprised by the ebb and flow, but the current extension installation system works pretty well, and the search feature on the toolbar helps with that. There has been a desire to make the extension hub open to third-party extensions, but the practical and legal issues with that have kept it from happening so far.
As for the added complexity issue, SPSSINC TRANS formulas are limited to a single function or expression, so more complex things such as a try/except block require writing a usually small begin/end program block with code that can then be invoked with SPSSINC TRANS. Of course, someone could write their own code with BEGIN PROGRAM to do anything they want without using SPSSINC TRANS, but that that command handles all the complexity of data transfers and creating new variables.