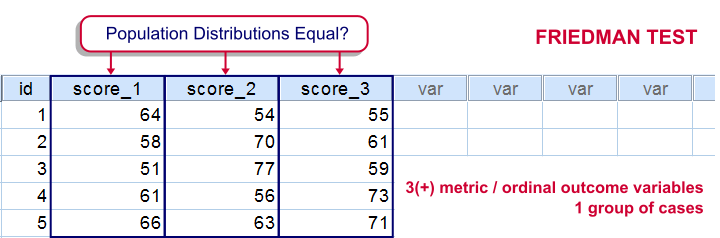
For testing if 3 or more variables have identical population means, our first option is a repeated measures ANOVA. This requires our data to meet some assumptions -like normally distributed variables. If such assumptions aren't met, then our second option is the Friedman test: a nonparametric alternative for a repeated-measures ANOVA.
Strictly, the Friedman test can be used on quantitative or ordinal variables but ties may be an issue in the latter case.
The Friedman Test - How Does it Work?
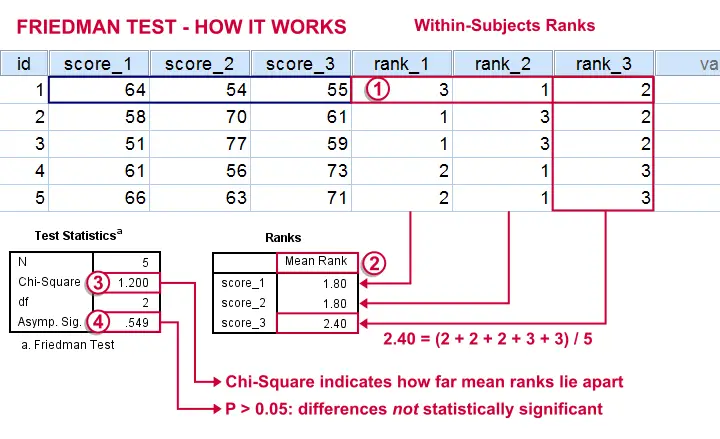
 The original variables are ranked within cases.
The original variables are ranked within cases.
 The mean ranks over cases are computed. If the original variables have similar distributions, then the mean ranks should be roughly equal.
The mean ranks over cases are computed. If the original variables have similar distributions, then the mean ranks should be roughly equal.
 The test-statistic, Chi-Square is like a variance over the mean ranks: it's 0 when the mean ranks are exactly equal and becomes larger as they lie further apart.In ANOVA we find a similar concept: the “mean square between” is basically the variance between sample means. This is explained in ANOVA - What Is It?.
The test-statistic, Chi-Square is like a variance over the mean ranks: it's 0 when the mean ranks are exactly equal and becomes larger as they lie further apart.In ANOVA we find a similar concept: the “mean square between” is basically the variance between sample means. This is explained in ANOVA - What Is It?.
 Asymp. Sig. is our p-value. It's the probability of finding our sample differences if the population distributions are equal. The differences in our sample have a large (0.55 or 55%) chance of occurring. They don't contradict our hypothesis of equal population distributions.
Asymp. Sig. is our p-value. It's the probability of finding our sample differences if the population distributions are equal. The differences in our sample have a large (0.55 or 55%) chance of occurring. They don't contradict our hypothesis of equal population distributions.
The Friedman Test in SPSS
Let's first take a look at our data in adratings.sav, part of which are shown below. The data contain 18 respondents who rated 3 commercials for cars on a percent (0% through 100% attractive) scale.
We'd like to know which commercial performs best in the population. So we'll first see if the mean ratings in our sample are different. If so, the next question is if they're different enough to conclude that the same holds for our population at large. That is, our null hypothesis is that the population distributions of our 3 rating variables are identical.
Quick Data Check
Inspecting the histograms of our rating variables will give us a lot of insight into our data with minimal effort. We'll create them by running the syntax below.
frequencies ad1 to ad3
/format notable
/histogram normal.
Result
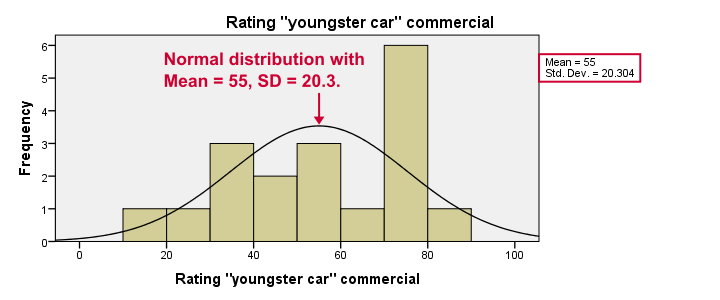
Most importantly, our data look plausible: we don't see any outrageous values or patterns. Note that the mean ratings are pretty different: 83, 55 and 66. Every histogram is based on all 18 cases so there's no missing values to worry about.
Now, by superimposing normal curves over our histograms, we do see that our variables are not quite normally distributed as required for repeated measures ANOVA. This isn't a serious problem for larger sample sizes (say, n > 25 or so) but we've only 18 cases now. We'll therefore play it safe and use a Friedman test instead.
Running a Friedman Test in SPSS
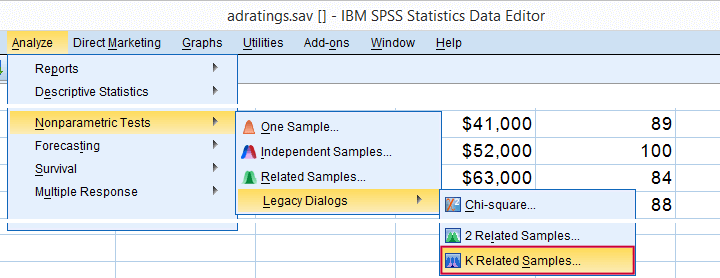
means that we'll compare 3 or more variables measured on the same respondents. This is similar to “within-subjects effect” we find in repeated measures ANOVA.
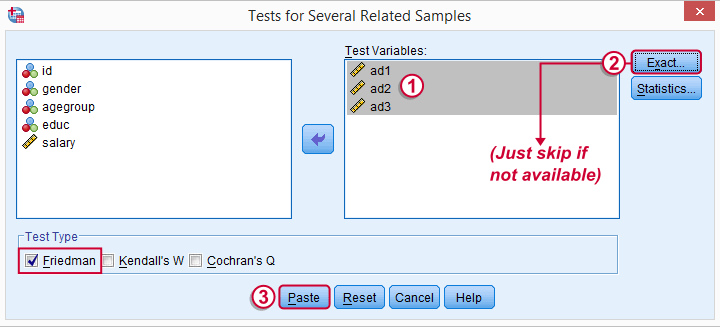
Depending on your SPSS license, you may or may not have the button. If you do, fill it out as below and otherwise just skip it.
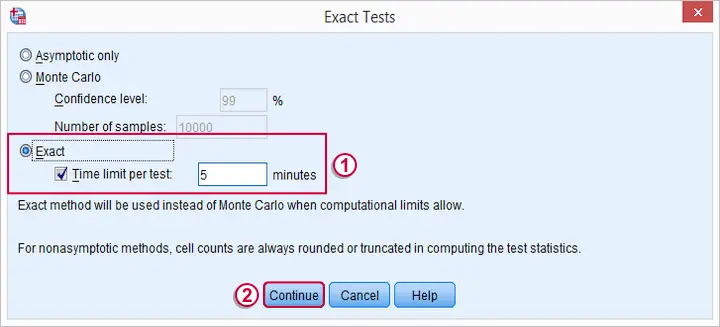
SPSS Friedman Test - Syntax
Following these steps results in the syntax below (you'll have 1 extra line if you selected the exact statistics). Let's run it.
NPAR TESTS
/FRIEDMAN=ad1 ad2 ad3
/MISSING LISTWISE.
SPSS Friedman Test - Output
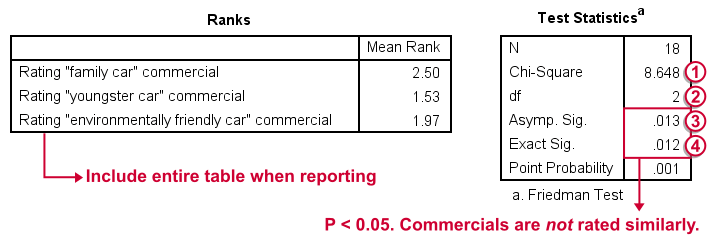
First note that the mean ranks differ quite a lot in favor of the first (“Family Car”) commercial. Unsurprisingly, the mean ranks have the same order as the means we saw in our histogram.
Chi-Square (more correctly referred to as Friedman’s Q) is our test statistic. It basically summarizes how differently our commercials were rated in a single number.
df are the degrees of freedom associated with our test statistic. It's equal to the number of variables we compare - 1. In our example, 3 variables - 1 = 2 degrees of freedom.
Asymp. Sig. is an approximate p-value. Since p < 0.05, we refute the null hypothesis of equal population distributions.“Asymp” is short for “asymptotic”: the more our sample size increases towards infinity, the more the sampling distribution of Friedman’s Q becomes similar to a χ2 distribution. Reversely, this χ2 approximation is less precise for smaller samples.
Exact Sig. is the exact p-value. If available, we prefer it over the asymptotic p-value, especially for smaller sample sizes.If there's an exact p-value, then why would anybody ever use an approximate p-value? The basic reason is that the exact p-value requires very heavy computations, especially for larger sample sizes. Modern computers deal with this pretty well but this hasn't always been the case.
Friedman Test - Reporting
As indicated previously, we'll include the entire table of mean ranks in our report. This tells you which commercial was rated best versus worst. Furthermore, we could write something like “a Friedman test indicated that our commercials were rated differently, χ2(2) = 8.65, p = 0.013.“ We personally disagree with this reporting guideline. We feel Friedman’s Q should be called “Friedman’s Q” instead of “χ2”. The latter is merely an approximation that may or may not be involved when calculating the p-value. Furthermore, this approximation becomes less accurate as the sample size decreases. Friedman’s Q is by no means the same thing as χ2 so we feel they should not be used interchangeably.
So much for the Friedman test in SPSS. I hope you found this tutorial useful. Thanks for reading.
THIS TUTORIAL HAS 20 COMMENTS:
By Subhankar Banerjee on June 28th, 2021
What's the name of the paired wise comparison statistics after getting a significant result (Friedman ANOVA for 3 samples)?
Example
Sample 1 vs Sample 2
Sample 2 vs Sample 3
Sample 3 vs Sample 1
By Ruben Geert van den Berg on June 28th, 2021
Hi Subhankar!
Andy Field claims that these pairwise tests are (Bonferroni corrected?) Wilcoxon signed-ranks tests.
For each comparison, Field reports the test statistic as "T".
However, you perhaps want to examine if these claims are correct: Field made similar claims regarding pairwise comparisons for the Kruskal-Wallis test and those were clearly wrong!
I think the correct formulas are in Sheskin, D. (2011). Handbook of Parametric and Nonparametric Statistical Procedures. Boca Raton, FL: Chapman & Hall/CRC. I don't have the time to verify if these correspond to the SPSS formulas but I think they do.
Hope that helps!
SPSS tutorials
By Hanna on April 29th, 2022
Hi! Thanks for the info.
By Help Assignment on March 20th, 2023
Amazing blog. This is going to help students a lot. We too started an initiative to encourage education among students With a lot of creative assignment help ideas .We are grateful for your wonderful blog. Your blog always exceeds my expectations. Your writing skills are amazing. It’s full of details.
By henryjhon on May 31st, 2025
Understanding non-parametric tests like the SPSS Friedman Test is crucial for data interpretation in evidence-based nursing. I found this tutorial especially useful while working on NURS FPX 4020 Assessment 4—it clarified so many doubts! Highly recommend this guide: NURS FPX 4020 Assessment 4. It’s a solid companion for mastering statistical methods in nursing practice.