- Setting Missing Values for String Variables
- Missing String Values and MEANS
- Missing String Values and CROSSTABS
- Missing String Values and COMPUTE
- Workarounds for Bugs
Can you set missing values for string variables in SPSS? Short answer: yes. Sadly, however, this doesn't work as it should. This tutorial walks you through some problems and fixes.
Example Data
All examples in this tutorial use staff.sav, partly shown below. We'll run some basic operations on Job Type (a string variable) and Marital Status (a numeric variable) in parallel.
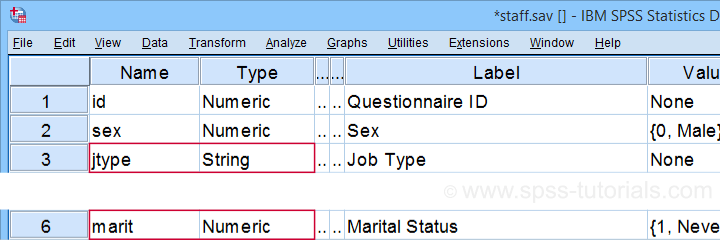
Let's first create basic some frequency distributions for both variables by running the syntax below.
frequencies marit jtype.
Result
Let's take a quick look at the frequency distribution for our string variable shown below.

By default, all values in a string variable are valid (not missing), including an empty string value of zero characters.
Setting Missing Values for String Variables
Now, let's suppose we'd like to set the empty string value and (Unknown) as user missing values. Experienced SPSS users may think that running missing values jtype ('','(Unknown)'). should do the job. Sadly, SPSS simply responds with a rather puzzling warning:
>The missing value is specified more than once.
First off, this warning is nonsensical: we didn't specify any missing value more than once. And even if we did. So what?
Second, the warning doesn't tell us the real problem. We'll find it out if we run
missing values jtype ('(Unknown)').
This triggers the warning below, which tells us that our user missing string value is simply too long.
>The missing value exceeds 8 bytes.
>Execution of this command stops.
A quick workaround for this problem is to simply RECODE '(Unknown)' into something shorter such as 'NA' (short for ‘Not Available”). The syntax below does just that. It then sets user missing values for Job Type and reruns the frequency tables.
recode jtype ('(Unknown)' = 'NA').
*Set 2 user missing values for string variable.
missing values jtype ('','NA').
*Quick check.
frequencies marit jtype.
Result
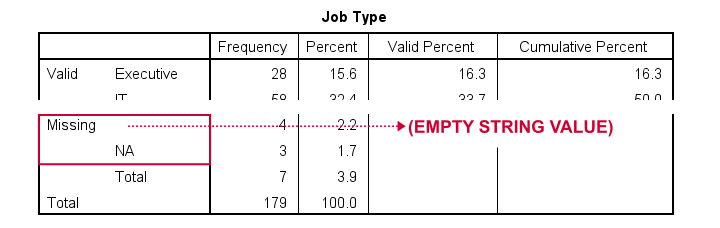
At this point, everything seems fine: both the empty string value and 'NA' are listed in the missing values section in our frequency table.
Missing String Values and MEANS
When running basic MEANS tables, user missing string values are treated as if they were valid. The syntax below demonstrates the problem:
means salary by marit jtype
/statistics anova.
Result
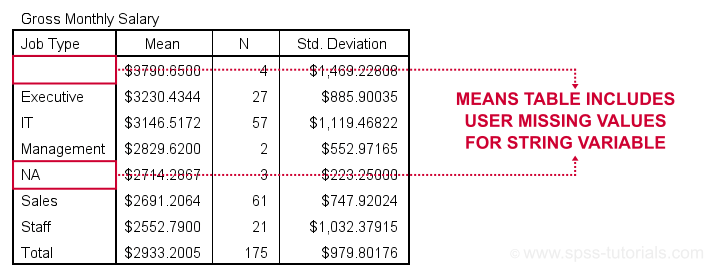
Note that user missing values are excluded in the first means table but included in the second means table. As this doesn't make sense and is not documented, I strongly suspect that this is a bug in SPSS.
Let's now try some CROSSTABS.
Missing String Values and CROSSTABS
We'll now run two basic contingency tables from the syntax below.
crosstabs marit jtype by sex.
Result
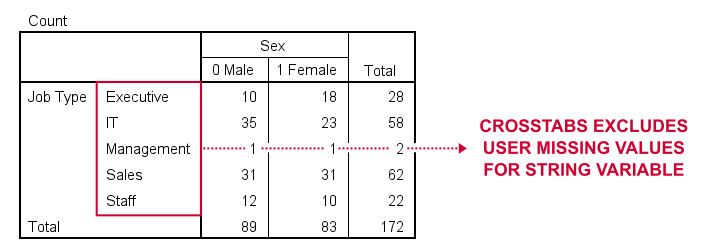
Basic conclusion: both tables fully exclude user missing values for our string and our numeric variables. This suggests that the aforementioned issue is restricted to MEANS. Unfortunately, however, there's more trouble...
Missing String Values and COMPUTE
A nice way to dichotomize variables is a single line COMPUTE as in
compute marr = (marit = 2).
In this syntax, (marit = 2) is a condition that may be false for some cases and true for others. SPSS returns 0 and 1 to represent false and true and hence creates a nice dummy variable.
Now, if marit is (system or user) missing, SPSS doesn't know if the condition is true and hence returns a system missing value on our new variable. Sadly, this doesn't work for string variables as demonstrated below.
compute marr = (marit = 2).
variable labels marr 'Currently married (yes/no)'.
frequencies marr.
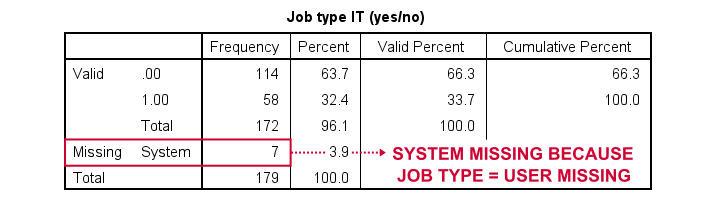
*Dichotomize string variable (incorrect result).
compute it = (jtype = 'IT').
variable labels it 'Job type IT (yes/no)'.
frequencies it.
A workaround for this problem is using IF. This shouldn't be necessary but it does circumvent the problem.
delete variables it.
*Dichotomize string variable (correct result).
if(not missing(jtype)) it = (jtype = 'IT').
variable labels it 'Job type IT (yes/no)'.
frequencies it.
Result
Workarounds for Bugs
The issues discussed in this tutorial are nasty; they may produce incorrect results that easily go unnoticed. A couple of ways to deal with them are the following:
- AUTORECODE string variables into numeric ones and proceed with these numeric counterparts.
- for creating tables and/or charts, exclude cases having string missing values with FILTER or even delete them altogether with SELECT IF.
- for creating new variables, IF and DO IF should suffice for most scenarios.
Right, I guess that should do regarding user missing string values. I hope you found my tutorial helpful. If you've any questions or comments, please throw us a comment below.
Thanks for reading!
THIS TUTORIAL HAS 9 COMMENTS:
By Jon K Peck on March 2nd, 2021
There is some strange behavior with string missing values, but, as documented in the CSR,
"String user-missing values are treated as missing by statistical and charting procedures and missing
values functions. They are treated as valid in other transformation expressions."
Second, the errouneous missing values command
missing values jtype ('', '(Unknown}').
seems to have contaminated the missing values stored for the variable. You can see that the missing values display in the DE Variable View shows a comma.
This cascades into the MEANS output, but if you start with a valid missing value specification for jtype, you can see that MEANS does recognize this and treat it correctly.
By Ruben Geert van den Berg on March 3rd, 2021
Hi Jon!
Did you actually run the MEANS command after setting the correct missing values for jtype? All user missings (empty string / NA) are included in the MEANS table but labeled as missing in FREQUENCIES. That's not what's supposed to happen. I wonder if any other procedures suffer from the same issue.
Also, if I run
MISSING VALUES jtype ('','(Unknown)').
then only the empty string value is set as user missing. The warning is nonsensical. It should tell me that '(Unknown)' contains too many bytes so I understand what's going wrong.
Also, "They are treated as valid in other transformation expressions." doesn't make sense. Why should you treat user missing values for string variables differently than for numeric variables? If I want SPSS to treat them as valid, I'll specify them as valid, right? This kinda defeats the point of user missing values in the first place...
By Jon K Peck on March 3rd, 2021
What I said about means included this
" but if you start with a valid missing value specification for jtype,"
Then MEANS behaves correctly. As I said, the problem appears to be due to the erroneous MISSING VALUES command. It contaminated the missing value specification in a way that tripped up MEANS. But the problem is not in the MEANS procedure. Reopen the data file and issue a valid MISSING VALUES command, and everything seems to be okay. I agree that the warning is wrong.
I have reported this to Development.
As for the treatment of missing values in transformation commands, I agree that it is weird. I think it has always been that way. I suspect that long ago, no missing values could be specified for strings, and when that was added (before my time), they probably didn't want to break compatibility with existing syntax, but that is just a guess.
image.png
By Ruben Geert van den Berg on March 4th, 2021
Hi Jon!
MEANS does not behave correctly on my SPSS version (27.0.0.0), even if missing values have been specified successfully as confirmed by FREQUENCIES.
So on staff.sav, I ran
*Change '(Unknown)' into 'NA'.
recode jtype ( '(Unknown)' = 'NA').
*Set empty string value and 'NA' as user missing values.
missing values jtype ('','NA').
*Reinspect basic frequency table.
frequencies jtype.
*At this point, NA and empty string are clearly user missing values. But then...
means salary by jtype.
*Still includes the empty string and NA.
P.s. seems you tried to add a .png file but the website doesn't support it. If you send it by email / URL, I'd like to have a look at it.
Thanks!!
By Cyrine Kheder on March 5th, 2021
Thanks