SPSS FILTER temporarily excludes a selection of cases
from all data analyses.
For excluding cases from data editing, use DO IF or IF instead.
Quick Overview Contents
- SPSS Filtering Basics
- Example 1 - Exclude Cases with Many Missing Values
- Example 2 - Filter on 2 Variables
- Example 3 - Filter without Filter Variable
- Tip - Commands with Built-In Filters
- Warning - Data Editing with Filter
SPSS FILTER - Example Data
I'll use bank_clean.sav -partly shown below- for all examples in this tutorial. This file contains the data from a small bank employee survey. Feel free to download these data and rerun the examples yourself.
SPSS Filtering Basics
Filtering in SPSS usually involves 4 steps:
- create a filter variable;
- activate the filter variable;
- run one or many analyses -such as correlations, ANOVA or a chi-square test- with the filter variable in effect;
- deactivate the filter variable.
In theory, any variable can be used as a filter variable. After activating it, cases with
- zeroes,
- user missing values or
- system missing values
on the filter variable are excluded from all analyses until you deactivate the filter. For the sake of clarity, I recommend you only use filter variables containing 0 or 1 for each case. Enough theory. Let's put things into practice.
Example 1 - Exclude Cases with Many Missing Values
At the end of our data, we find 9 rating scales: q1 to q9. Perhaps we'd like to run a factor analysis on them or use them as predictors in regression analysis. In any case, we may want to exclude cases having many missing values on these variables. We'll first just count them by running the syntax below.
compute mis_1 = nmiss(q1 to q9).
*Apply variable label.
variable labels mis_1 'Number of missings on q1 to q9'.
*Check frequencies.
frequencies mis_1.
Result

Based on this frequency distribution, we decided to exclude the 8 cases having 3 or more missing values on q1 to q9. We'll create our filter variable with a simple RECODE as shown below.
recode mis_1 (lo thru 2 = 1)(else = 0) into filt_1.
*Apply variable label.
variable labels filt_1 'Filter out cases with 3 or more missings on q1 to q9'.
*Activate filter variable.
filter by filt_1.
*Reinspect numbers of missings over q1 to q9.
frequencies mis_1.
Result
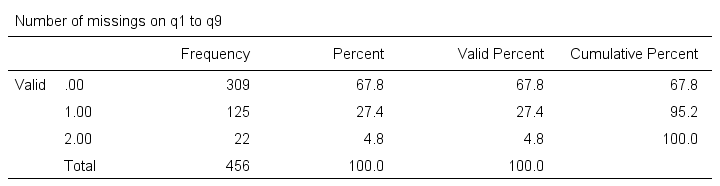
Note that SPSS now reports 456 instead of 464 cases. The 8 cases with 3 or more missing values are still in our data but they are excluded from all analyses. We can see why in data view as shown below.
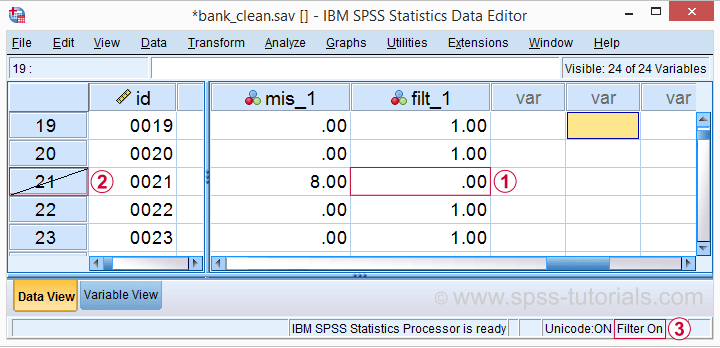
 Case 21 has 8 missing values on q1 to q9 and we recoded this into zero on our filter variable.
Case 21 has 8 missing values on q1 to q9 and we recoded this into zero on our filter variable.
 The strikethrough its $casenum shows that case 21 is currently filtered out.
The strikethrough its $casenum shows that case 21 is currently filtered out.
 The status bar confirms that a filter variable is in effect.
Finally, let's deactivate our filter by simply running
FILTER OFF.
We'll leave our filter variable filt_1 in the data. It won't bother us in any way.
The status bar confirms that a filter variable is in effect.
Finally, let's deactivate our filter by simply running
FILTER OFF.
We'll leave our filter variable filt_1 in the data. It won't bother us in any way.
Example 2 - Filter on 2 Variables
For some other analysis, we'd like to use only female respondents working in sales or marketing. A good starting point is running a very simple contingency table as shown below.
set tnumbers both.
*Show frequencies for job type per gender.
crosstabs gender by jtype.
Result

As our table shows, we've 181 female respondents working in either sales or marketing. We'll now create a new filter variable holding only zeroes. We'll then set it to 1 for our case selection with a simple IF command.
compute filt_2 = 0.
*Set filter to 1 for females in job types 1 and 2.
if(gender = 0 & jtype <= 2) filt_2 = 1.
*Apply variable label.
variable labels filt_2 'Filter in females working in sales and marketing'.
*Activate filter.
filter by filt_2.
*Confirm filter working properly.
crosstabs gender by jtype.
Rerunning our contingency table (not shown) confirms that SPSS now reports only 181 female cases working in marketing or sales. Also note that we now have 2 filter variables in our data and that's just fine but only 1 filter variable can be active at any time. Ok. Let's deactivate our new filter variable as well with FILTER OFF.
Example 3 - Filter without Filter Variable
Experienced SPSS users may know that
- TEMPORARY can “undo” some data editing that follow it and
- SELECT IF permanently deletes cases from your data.
By combining them you can circumvent the need for creating a filter variable but for 1 analysis at the time only. The example below shows just that: the first CROSSTABS is limited to a selection of cases but also rolls back our case deletion. The second CROSSTABS therefore includes all cases again.
temporary.
*Delete cases unless gender = 1 & jtype = 3.
select if (gender = 1 & jtype = 3).
*Crosstabs includes only males in IT and rolls back case selection.
crosstabs gender by jtype.
*Crosstabs includes all cases again.
crosstabs gender by jtype.
Tip - Commands with Built-In Filters
Something else you may want to know is that some commands have a built-in filter. These are
- REGRESSION,
- LOGISTIC REGRESSION,
- FACTOR and
- DISCRIMINANT.
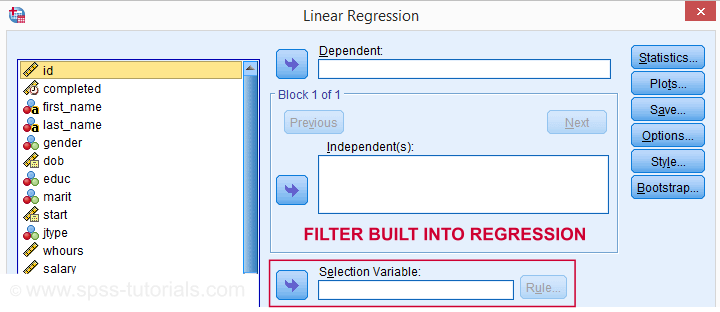
The dialog suggests you can filter cases -for this command only- based on just 1 variable. I suspect you can enter more complex conditions on the resulting /SELECT subcommand as well. I haven't tried it.
In any case, I think these built-in filters can be very handy and it kinda puzzles me they're only limited to the 4 aforementioned commands.
Warning - Data Editing with Filter
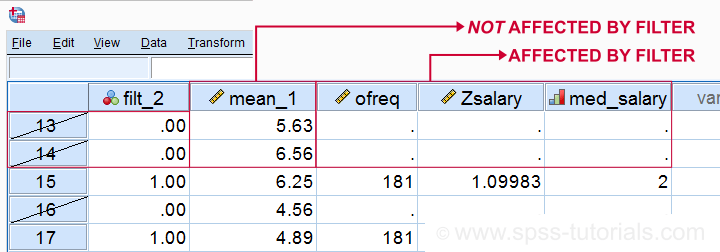
Most data editing in SPSS is unaffected by filtering. For example, computing means over variables -as shown below- affects all cases, regardless of whatever filter is active. We therefore need DO IF or IF to restrict this transformation to a selection of cases. However, an active filter does affect functions over cases. Some examples that we'll demonstrate below are
- adding a case count with AGGREGATE;
- computing z-scores for one or many variables;
- adding ranks, or percentiles with RANK.
SPSS Data Editing Affected by Filter Examples
filter by filt_2.
*Not affected by filter: add mean over q1 to q9 to data.
compute mean_1 = mean(q1 to q9).
execute.
*Affected by filter: add case count to data.
aggregate outfile * mode addvariables
/ofreq = n.
*Affected by filter: add z-scores salary to data..
descriptives salary
/save.
*Affected by filter: add median groups salary to data.
rank salary
/ntiles(2) into med_salary.
Result
Right. So that's pretty much all about filtering in SPSS. I hope you found this tutorial helpful and
Thanks for reading!
THIS TUTORIAL HAS 27 COMMENTS:
By Jon Peck on November 1st, 2023
Just to summarize: selection such as FILTER affects procedures but not data transformations. A procedure is any command that forces a data pass.
By Ruben Geert van den Berg on November 2nd, 2023
Yes, I'm well aware of that but I'm not sure how many visitors truly understand "procedures" versus "transformations".
For those, I considered mentioning
-functions over cases (in data view these are vertical functions) versus
-functions over variables (horizontal functions).
For the former, I found
-z-scores from DESCRIPTIVES
-RANK (ranks or ntiles over cases as new variables)
-AGGREGATE (statistics over cases as new variables)
-AUTORECODE (recode string values into numbers & labels)
but I'm probably missing a couple here...
P.s. how's the situation with your ribs? Did you recover (partially)? Can you do the normal things in life and/or sports yet?