- Setting Missing Values for String Variables
- Missing String Values and MEANS
- Missing String Values and CROSSTABS
- Missing String Values and COMPUTE
- Workarounds for Bugs
Can you set missing values for string variables in SPSS? Short answer: yes. Sadly, however, this doesn't work as it should. This tutorial walks you through some problems and fixes.
Example Data
All examples in this tutorial use staff.sav, partly shown below. We'll run some basic operations on Job Type (a string variable) and Marital Status (a numeric variable) in parallel.
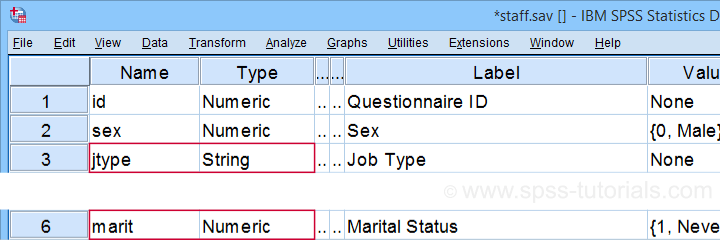
Let's first create basic some frequency distributions for both variables by running the syntax below.
frequencies marit jtype.
Result
Let's take a quick look at the frequency distribution for our string variable shown below.

By default, all values in a string variable are valid (not missing), including an empty string value of zero characters.
Setting Missing Values for String Variables
Now, let's suppose we'd like to set the empty string value and (Unknown) as user missing values. Experienced SPSS users may think that running missing values jtype ('','(Unknown)'). should do the job. Sadly, SPSS simply responds with a rather puzzling warning:
>The missing value is specified more than once.
First off, this warning is nonsensical: we didn't specify any missing value more than once. And even if we did. So what?
Second, the warning doesn't tell us the real problem. We'll find it out if we run
missing values jtype ('(Unknown)').
This triggers the warning below, which tells us that our user missing string value is simply too long.
>The missing value exceeds 8 bytes.
>Execution of this command stops.
A quick workaround for this problem is to simply RECODE '(Unknown)' into something shorter such as 'NA' (short for ‘Not Available”). The syntax below does just that. It then sets user missing values for Job Type and reruns the frequency tables.
recode jtype ('(Unknown)' = 'NA').
*Set 2 user missing values for string variable.
missing values jtype ('','NA').
*Quick check.
frequencies marit jtype.
Result
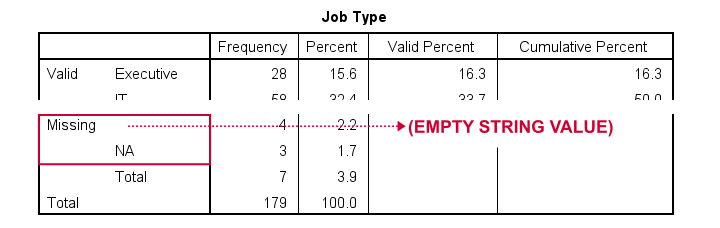
At this point, everything seems fine: both the empty string value and 'NA' are listed in the missing values section in our frequency table.
Missing String Values and MEANS
When running basic MEANS tables, user missing string values are treated as if they were valid. The syntax below demonstrates the problem:
means salary by marit jtype
/statistics anova.
Result
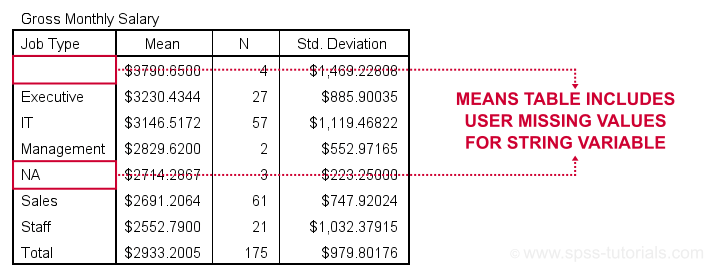
Note that user missing values are excluded in the first means table but included in the second means table. As this doesn't make sense and is not documented, I strongly suspect that this is a bug in SPSS.
Let's now try some CROSSTABS.
Missing String Values and CROSSTABS
We'll now run two basic contingency tables from the syntax below.
crosstabs marit jtype by sex.
Result
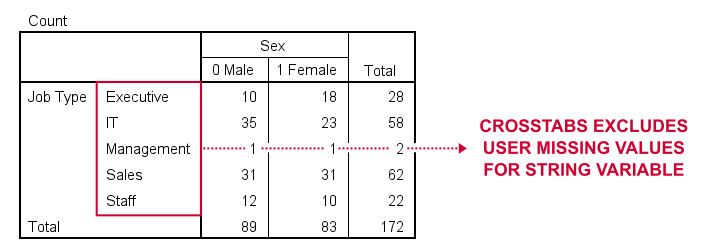
Basic conclusion: both tables fully exclude user missing values for our string and our numeric variables. This suggests that the aforementioned issue is restricted to MEANS. Unfortunately, however, there's more trouble...
Missing String Values and COMPUTE
A nice way to dichotomize variables is a single line COMPUTE as in
compute marr = (marit = 2).
In this syntax, (marit = 2) is a condition that may be false for some cases and true for others. SPSS returns 0 and 1 to represent false and true and hence creates a nice dummy variable.
Now, if marit is (system or user) missing, SPSS doesn't know if the condition is true and hence returns a system missing value on our new variable. Sadly, this doesn't work for string variables as demonstrated below.
compute marr = (marit = 2).
variable labels marr 'Currently married (yes/no)'.
frequencies marr.
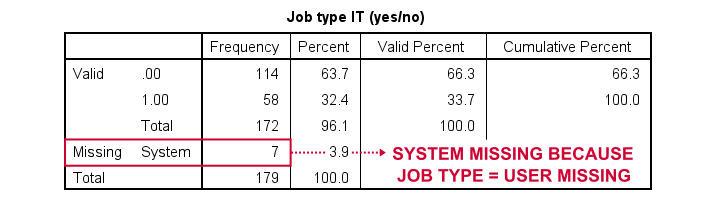
*Dichotomize string variable (incorrect result).
compute it = (jtype = 'IT').
variable labels it 'Job type IT (yes/no)'.
frequencies it.
A workaround for this problem is using IF. This shouldn't be necessary but it does circumvent the problem.
delete variables it.
*Dichotomize string variable (correct result).
if(not missing(jtype)) it = (jtype = 'IT').
variable labels it 'Job type IT (yes/no)'.
frequencies it.
Result
Workarounds for Bugs
The issues discussed in this tutorial are nasty; they may produce incorrect results that easily go unnoticed. A couple of ways to deal with them are the following:
- AUTORECODE string variables into numeric ones and proceed with these numeric counterparts.
- for creating tables and/or charts, exclude cases having string missing values with FILTER or even delete them altogether with SELECT IF.
- for creating new variables, IF and DO IF should suffice for most scenarios.
Right, I guess that should do regarding user missing string values. I hope you found my tutorial helpful. If you've any questions or comments, please throw us a comment below.
Thanks for reading!
THIS TUTORIAL HAS 9 COMMENTS:
By Robin Rai on June 10th, 2021
impressive tutorial on SPSS – Missing Values for String Variables
By Jon K Peck on August 15th, 2022
On the MEANS example, that NA category does not appear in the upcoming release (29).
The second issue, compute marr = (marit = 2). is subtle.
String variables do not support sysmis. If marit were numeric and the value was sysmis, the result would be sysmis. But for a string, this text from the CSR explains the rule.
User-missing string values are treated the same as nonmissing string values when evaluating string variables in logical expressions. In other words, all string variable values are treated as valid, nonmissing values in logical expressions.
In your example, marit = 2,
this expression can be evaluated unambiguously for "NA". The value is not 2.
It would be nice if strings supported sysmis, in which case a sysmis value would produce sysmis in the result, but sysmis is handled with a special internal representation that requires a numerical evaluation.
By Ruben Geert van den Berg on August 17th, 2022
Hi Jon!
"On the MEANS example, that NA category does not appear in the upcoming release (29)."
Ok, but doesn't that violate backwards compatibility? Users could rely on the "old" (somewhat unlogical) output, right?
But then again, being overly obsessed with backward compatibility may preclude progress too as with Python2 and Python3. IMHO, they did the right thing and perhaps SPSS should do something similar some day.
Also, I think a pretty simple workaround for the COMPUTEs is something like
if(not missing(marit)) marit_1 = (marit = 1).
I believe I implemented just that to make things work as I wanted but I was a little disappointed that this was necessary in the first place.
By Jon K Peck on August 17th, 2022
I think the MEANS issue was considered a bug.
It's always a concern when a change might break backwards compatibility. The only time in my memory where there was a significant incompatibility break was in version 16, when the entire Viewer mechanism was replaced (actually the entire frontend was rewritten). That had to be done to accommodate non-Windows platforms effectively as well as to improve the internal architecture.
Unicode was made the default encoding in V21, but it had been available since 16, and users could change that back to code page.
The Python 2-3 change, which was a good thing, had to be done, because Python 2 had reached end of support from the PSF, but there is a conversion tool extension command that handles most of the change.