A chi-square goodness-of-fit test examines if a categorical variable
has some hypothesized frequency distribution in some population.
The chi-square goodness-of-fit test is also known as
Example - Testing Car Advertisements
A car manufacturer wants to launch a campaign for a new car. They'll show advertisements -or “ads”- in 4 different sizes. For ad each size, they have 4 ads that try to convey some message such as “this car is environmentally friendly”. They then asked N = 80 people which ad they liked most. The data thus obtained are in this Googlesheet, partly shown below.
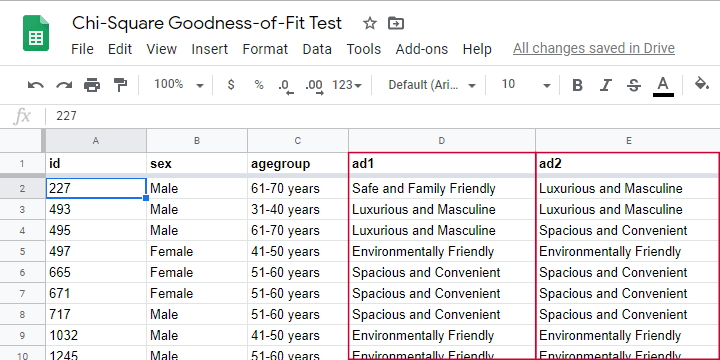
So which ads performed best in our sample? Well, we can simply look up which ad was preferred by most respondents: the ad having the highest frequency is the mode for each ad size.
So let's have a look at the frequency distribution for the first ad size -ad1- as visualized in the bar chart shown below.
Observed Frequencies and Bar Chart
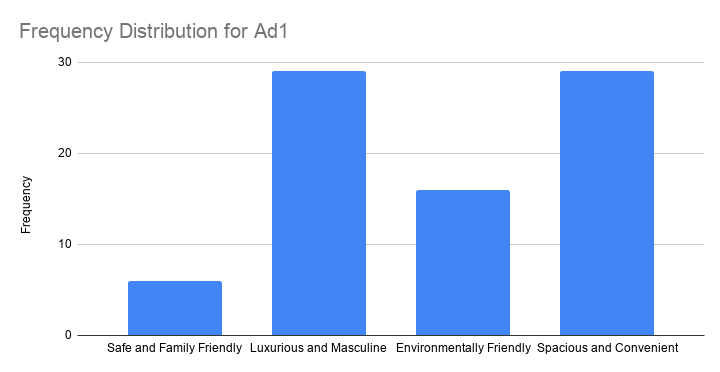
The observed frequencies shown in this chart are
- Safe and Family Friendly: 6
- Luxurious and Masculine: 29
- Environmentally Friendly: 16
- Spacious and Convenient: 29
Note that ad1 has a bimodal distribution: ads 2 and 4 are both winners with 29 votes. However, our data only hold a sample of N = 80. So
can we conclude that ads 2 and 4
also perform best in the entire population?
The chi-square goodness-of-fit answers just that. And for this example, it does so by trying to reject the null hypothesis that all ads perform equally well in the population.
Null Hypothesis
Generally, the null hypothesis for a chi-square goodness-of-fit test is simply
$$H_0: P_{01}, P_{02},...,P_{0m},\; \sum_{i=0}^m\biggl(P_{0i}\biggr) = 1$$
where \(P_{0i}\) denote population proportions for \(m\) categories in some categorical variable. You can choose any set of proportions as long as they add up to one. In many cases, all proportions being equal is the most likely null hypothesis.
For a dichotomous variable having only 2 categories, you're better off using
- a binomial test because it gives the exact instead of the approximate significance level or
- a z-test for 1 proportion because it gives a confidence interval for the population proportion.
Anyway, for our example, we'd like to show that some ads perform better than others. So we'll try to refute that our 4 population proportions are all equal and -hence- 0.25.
Expected Frequencies
Now, if the 4 population proportions really are 0.25 and we sample N = 80 respondents, then we expect each ad to be preferred by 0.25 · 80 = 20 respondents. That is, all 4 expected frequencies are 20. We need to know these expected frequencies for 2 reasons:
- computing our test statistic requires expected frequencies and
- the assumptions for the chi-square goodness-of-fit test involve expected frequencies as well.
Assumptions
The chi-square goodness-of-fit test requires 2 assumptions2,3:
- independent observations;
- for 2 categories, each expected frequency \(Ei\) must be at least 5.
For 3+ categories, each \(Ei\) must be at least 1 and no more than 20% of all \(Ei\) may be smaller than 5.
The observations in our data are independent because they are distinct persons who didn't interact while completing our survey. We also saw that all \(Ei\) are (0.25 · 80 =) 20 for our example. So this second assumption is met as well.
Formulas
We'll first compute the \(\chi^2\) test statistic as
$$\chi^2 = \sum\frac{(O_i - E_i)^2}{E_i}$$
where
- \(O_i\) denotes the observed frequencies and
- \(E_i\) denotes the expected frequencies -usually all equal.
For ad1, this results in
$$\chi^2 = \frac{(16 - 20)^2}{20} + \frac{(29 - 20)^2}{20} + \frac{(9 - 20)^2}{20} + \frac{(29 - 20)^2}{20} = 18.7 $$
If all assumptions have been met, \(\chi^2\) approximately follows a chi-square distribution with \(df\) degrees of freedom where
$$df = m - 1$$
for \(m\) frequencies. Since we have 4 frequencies for 4 different ads,
$$df = 4 - 1 = 3$$
for our example data. Finally, we can simply look up the significance level as
$$P(\chi^2(3) > 18.7) \approx 0.00032$$
We ran these calculations in this Googlesheet shown below.
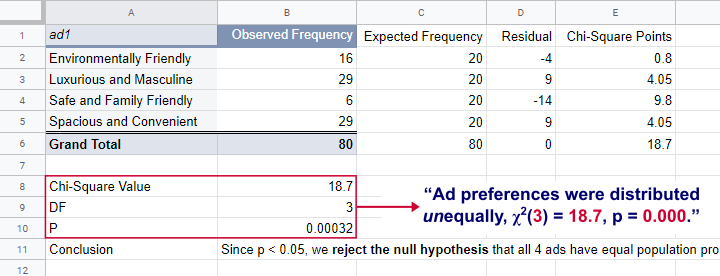
So what does this mean? Well, if all 4 ads are equally preferred in the population, there's a 0.00032 chance of finding our observed frequencies. Since p < 0.05, we reject the null hypothesis. Conclusion: some ads are preferred by more people than others in the entire population of readers.
Right, so it's safe to assume that the population proportions are not all equal. But precisely how different are they? We can express this in a single number: the effect size.
Effect Size - Cohen’s W
The effect size for a chi-square goodness-of-fit test -as well as the chi-square independence test- is Cohen’s W. Some rules of thumb1 are that
- Cohen’s W = 0.10 indicates a small effect size;
- Cohen’s W = 0.30 indicates a medium effect size;
- Cohen’s W = 0.50 indicates a large effect size.
Cohen’s W is computed as
$$W = \sqrt{\sum_{i = 1}^m\frac{(P_{oi} - P_{ei})^2}{P_{ei}}}$$
where
- \(P_{oi}\) denote observed proportions and
- \(P_{ei}\) denote expected proportions under the null hypothesis for
- \(m\) cells.
For ad1, the null hypothesis states that all expected proportions are 0.25. The observed proportions are computed from the observed frequencies (see screenshot below) and result in
$$W = \sqrt{\frac{(0.2 - 0.25)^2}{0.25} +\frac{(0.3625 - 0.25)^2}{0.25} +\frac{(0.075 - 0.25)^2}{0.25} +\frac{(0.3625 - 0.25)^2}{0.25} } = $$
$$W = \sqrt{0.234} = 0.483$$
We ran these computations in this Googlesheet shown below.

For ad1, the effect size \(W\) = 0.483. This indicates a large overall difference between the observed and expected frequencies.
Power and Sample Size Calculation
Now that we computed our effect size, we're ready for our last 2 steps. First off, what about power? What's the probability demonstrating an effect if
- we test at α = 0.05;
- we have a sample of N = 80;
- df = 3 (our outcome variable has 4 categories);
- we don't know the population effect size \(W\)?
The chart below -created in G*Power- answers just that.
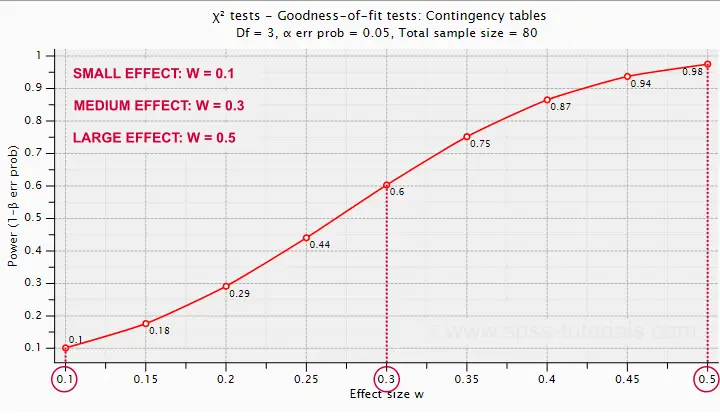
Some basic conclusions are that
- power = 0.98 for a large effect size;
- power = 0.60 for a medium effect size;
- power = 0.10 for a small effect size.
These outcomes are not too great: we only have a 0.60 probability of rejecting the null hypothesis if the population effect size is medium and N = 80. However, we can increase power by increasing the sample size. So which sample sizes do we need if
- we test at α = 0.05;
- we want to have power = 0.80;
- df = 3 (our outcome variable has 4 categories);
- we don't know the population effect size \(W\)?
The chart below shows how required sample sizes decrease with increasing effect sizes.
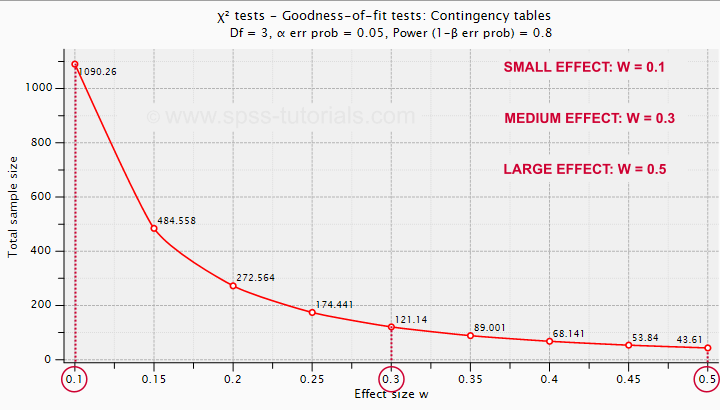
Under the aforementioned conditions, we have power ≥ 0.80
- for a large effect size if N = 44;
- for a medium effect size if N = 122;
- for a small effect size if N = 1091.
References
- Cohen, J (1988). Statistical Power Analysis for the Social Sciences (2nd. Edition). Hillsdale, New Jersey, Lawrence Erlbaum Associates.
- Siegel, S. & Castellan, N.J. (1989). Nonparametric Statistics for the Behavioral Sciences (2nd ed.). Singapore: McGraw-Hill.
- Warner, R.M. (2013). Applied Statistics (2nd. Edition). Thousand Oaks, CA: SAGE.
THIS TUTORIAL HAS 9 COMMENTS:
By Olorunfemi Adebayo on April 9th, 2020
Good explaination
By Manuel on April 14th, 2020
I understand the theory, but, I miss an explanation about why this test is a one-tailed test, namely, with a right-sided tail. Wouldn't it be possible to work as a two-sided test?
Thank you
By Ruben Geert van den Berg on April 15th, 2020
Hi Manuel!
Great question!
The basic answer is that for a t-distribution and a standard normal distribution, very low or very high outcomes are both unlikely: they both indicate large differences between the null hypothesis and the data. Both distributions are symmetrical around zero which indicates no deviation from the null hypothesis at all.
Now, the f-distribution and chi-square distribution are basically squared distributions. So very low values -after squaring- become very high values. That's why both have a minimum of zero which indicates no deviation from the null hypothesis at all and p = 1.000.
As a result, larger deviations -in whatever direction- from the null hypothesis always result in larger chi-square or F-values. So for these distributions we always report right-tailed significance.
This was also explained in Statistical Significance - What Does It Really Mean?
Hope that helps!
SPSS tutorials
By Muhammed Tahir Muhammed on April 6th, 2022
This analysis and explanation are of standard. Please I will like to be receiving mail from you mentor.