- Downloading & Installing PROCESS
- Creating Tables instead of Text Output
- Using PROCESS with Syntax
- PROCESS Model Numbers
- PROCESS & Dummy Coding
- Strengths & Weaknesses of PROCESS
What is PROCESS?
PROCESS is a freely downloadable SPSS tool for estimating regression models with mediation and/or moderation effects. An example of such a model is shown below.
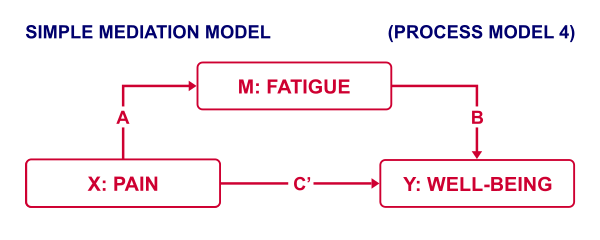
This model can fairly easily be estimated without PROCESS as discussed in SPSS Mediation Analysis Tutorial. However, using PROCESS has some advantages (as well as disadvantages) over a more classical approach. So how to get PROCESS and how does it work?
Those who want to follow along may download and open wellbeing.sav, partly shown below.
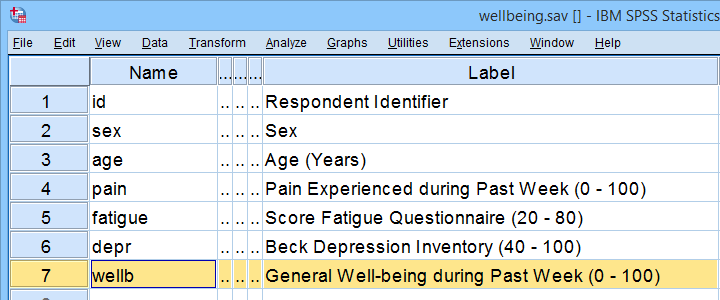
Note that this tutorial focuses on becoming proficient with PROCESS. The example analysis will be covered in a future tutorial.
Downloading & Installing PROCESS
PROCESS can be downloaded here (scroll down to “PROCESS macro for SPSS, SAS, and R”). The download comes as a .zip file which you first need to unzip. After doing so, in SPSS, navigate to
![]()
![]() Select “process.spd” and click “Open” as shown below.
Select “process.spd” and click “Open” as shown below.
This should work for most SPSS users on recent versions. If it doesn't, consult the installation instructions that are included with the download.
Running PROCESS
If you successfully installed PROCESS, you'll find it in the regression menu as shown below.
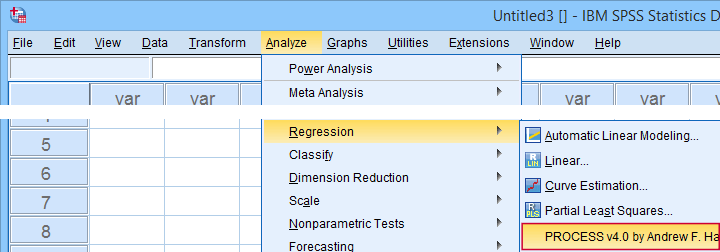
For a very basic mediation analysis, we fill out the dialog as shown below.
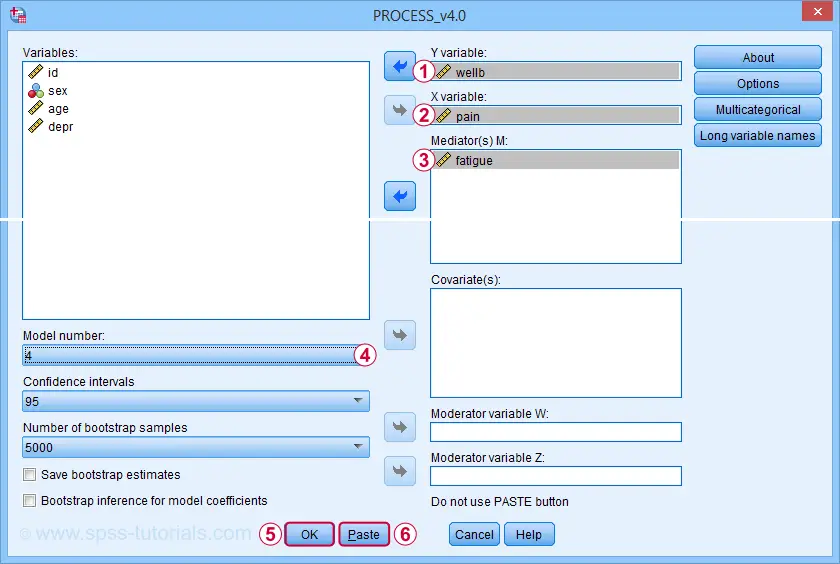
 Y refers to the dependent (or “outcome”) variable;
Y refers to the dependent (or “outcome”) variable;
 X refers to the independent variable or “predictor” in a regression context;
X refers to the independent variable or “predictor” in a regression context;
 For simple mediation, select model 4. We'll have a closer look at model numbers in a minute;
For simple mediation, select model 4. We'll have a closer look at model numbers in a minute;
 Just for now, let's click “Ok”.
Just for now, let's click “Ok”.
Result
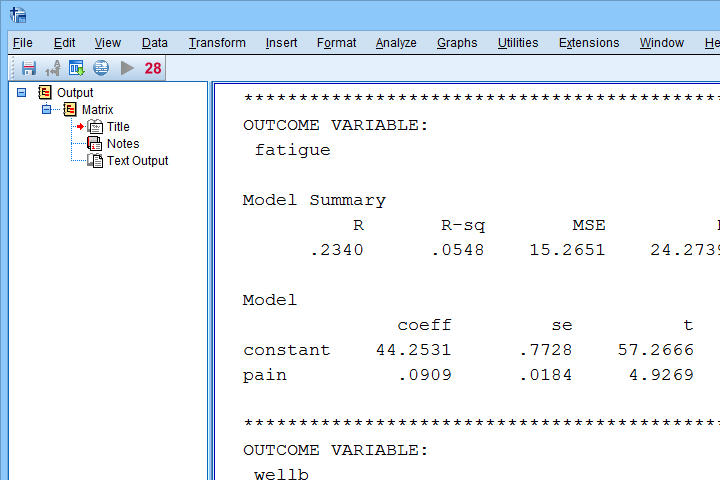
The first thing that may strike you, is that the PROCESS output comes as plain text. This is awkward because formatting it is very tedious and you can't adjust any decimal places. So let's fix that.
Creating Tables instead of Text Output
If you're using SPSS version 24 or higher, run the following SPSS syntax: set mdisplay tables. After doing so, running PROCESS will result in normal SPSS output tables rather than plain text as shown below.
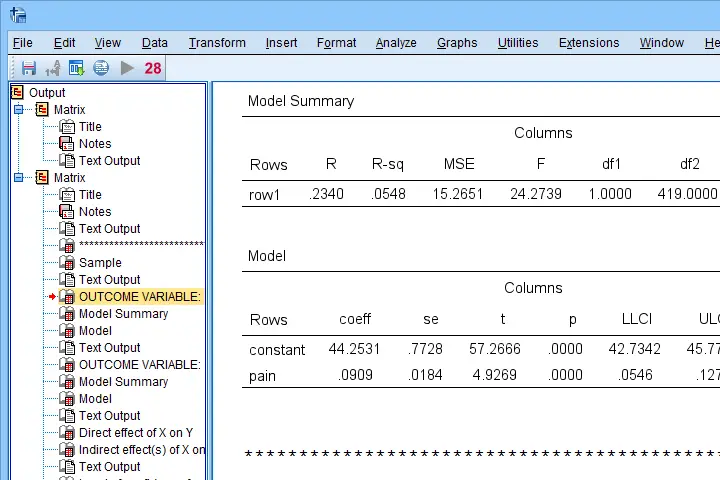
Note that you can readily copy-paste these tables into Excel and/or adjust their decimal places.
Using PROCESS with Syntax
First off: whatever you do in SPSS, save your syntax. Now, like any other SPSS dialog, PROCESS has a Paste button for pasting its syntax. However, a huge stupidity from the programmers is that doing so results in some 6,140 (!) lines of syntax. I'll add the first lines below.
/* Written by Andrew F Hayes */.
/* www.afhayes.com */.
/* www.processmacro.org */.
/* Copyright 2017-2021 by Andrew F Hayes */.
/* Documented in http://www.guilford.com/p/hayes3 */.
/* THIS CODE SHOULD BE DISTRIBUTED ONLY THROUGH PROCESSMACRO.ORG */.
You can run and save this syntax but having over 6,140 lines is awkward. Now, this huge syntax basically consists of 2 parts:
- a macro definition of some 6,130 lines: this consists of the formulas and computations that are performed on the input (variables, models and so on) that the SPSS user specifies;
- a macro call of some 10 lines: this tells SPSS to run the macro and which input to use.
The macro call is at the very end of the pasted syntax (use the Ctrl + End shortcut in your syntax window) and looks as follows.
y=wellb
/x=pain
/m=fatigue
/decimals=F10.4
/boot=5000
/conf=95
/model=4.
After you run the (huge) macro definition just once during your session, you only need one (short) macro call for every PROCESS model you'd like to run.
A nice way to implement this, is to move the entire macro definition into a separate SPSS syntax file. Those who want to try this can download DEFINE-PROCESS-40.sps.
Although technically not mandatory, macro names should really start with exclamation marks. Therefore, we replaced DEFINE PROCESS with DEFINE !PROCESS in line 2,983 of this file. The final trick is that we can run this huge syntax file without opening it by using the INSERT command. Like so, the syntax below replicates our entire first PROCESS analysis.
insert file = 'd:/downloaded/DEFINE-PROCESS-40.sps'.
*RERUN FIRST PROCESS ANALYSIS.
!PROCESS
y=wellb
/x=pain
/m=fatigue
/decimals=F10.4
/boot=5000
/conf=95
/model=4.
Note: for replicating this, you may need to replace d:/downloaded by the folder where DEFINE-PROCESS-40.sps is located on your computer.
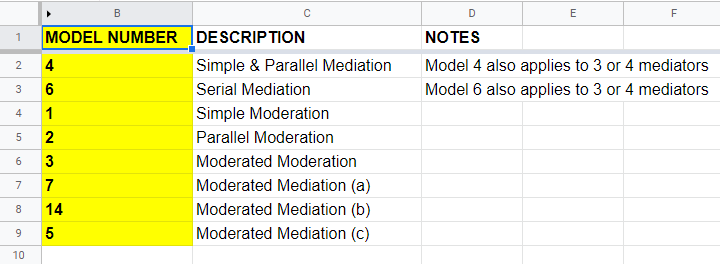
PROCESS Model Numbers
As we speak, PROCESS implements 94 models. An overview of the most common ones is shown in this Googlesheet (read-only), partly shown below.
For example, if we have an X, Y and 2 mediator variables, we may hypothesize parallel mediation as illustrated below.
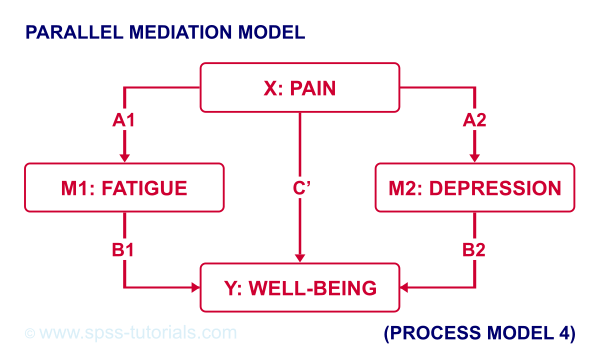
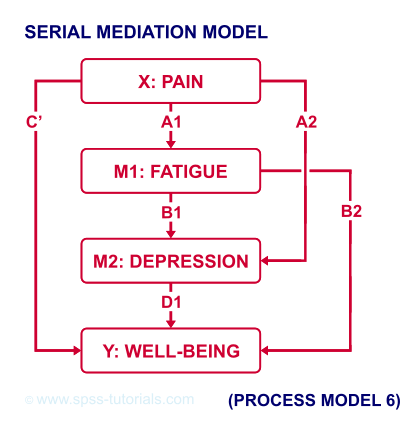
However, you could also hypothesize that mediator 1 affects mediator 2 which, in turn, affects Y. If you want to test this serial mediation effect, select model 6 in PROCESS.
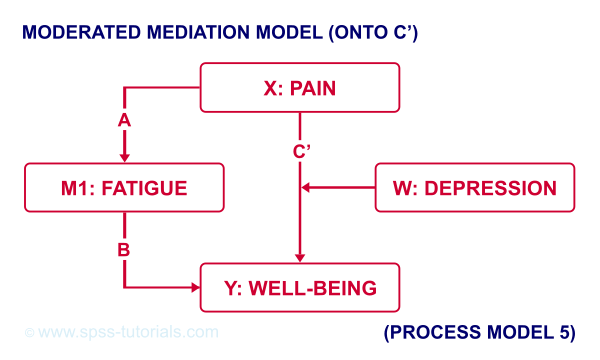
For moderated mediation, things get more complicated: the moderator could act upon any combination of paths a, b or c’. If you believe the moderator only affects path c’, choose model 5 as shown below.
An overview of all model numbers is given in this book.
PROCESS & Dummy Coding
A quick overview of variable types for PROCESS is shown in this Googlesheet (read-only), partly shown below.
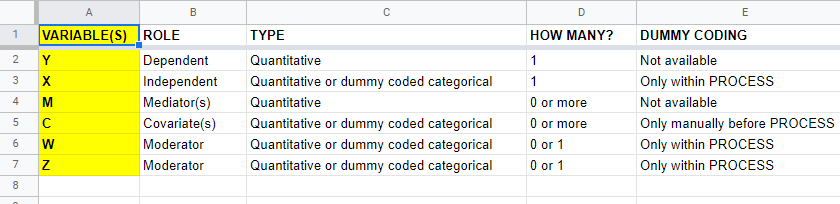
Keep in mind that PROCESS is entirely based on linear regression. This requires that dependent variables are quantitative (interval or ratio measurement level). This includes mediators, which act as both dependent and independent variables.
All other variables
- may be quantitative;
- may be dichotomous (preferably coded as 0-1);
- or must be dummy coded (nominal and ordinal variables).
X and moderator variables W and Z can only be dummy coded within PROCESS as shown below.
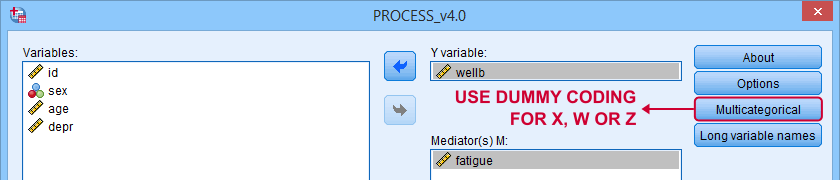
Covariates must be dummy coded before using PROCESS. For a handy tool, see SPSS Create Dummy Variables Tool.
Making Bootstrapping Replicable
Some PROCESS models rely on bootstrapping for reporting confidence intervals. Very basically, bootstrapping comes down to
- drawing a simple random sample (with replacement) from the data;
- computing statistics (for PROCESS, these are b-coefficients) on this new sample;
- repeating this procedure many (typically 1,000 - 10,000) times;
- examining to what extent each statistic fluctuates over these bootstrap samples.
Like so, a 95% bootstrapped CI for some parameter consists of the [2.5th - 97.5th] percentiles for some statistic over the bootstrap samples.
Now, due to the random nature of bootstrapping, running a PROCESS model twice typically results in slightly different CI's. This is undesirable but a fix is to add a /SEED subcommand to the macro call as shown below.
y=wellb
/x=pain
/m=fatigue
/decimals=F10.4
/boot=5000
/conf=95
/model=4
/seed = 20221227. /*MAKE BOOTSTRAPPED CI'S REPLICABLE*/
The random seed can be any positive integer. Personally, I tend to use the current date in YYYYMMDD format (20221227 is 27 December, 2022). An alternative is to run something like SET SEED 20221227. before running PROCESS. In this case, you need to prevent PROCESS from overruling this random seed, which you can do by replacing set seed = !seed. by *set seed = !seed. in line 3,022 of the macro definition.
Strengths & Weaknesses of PROCESS
A first strength of PROCESS is that it can save a lot of time and effort. This holds especially true for more complex models such as serial and moderated mediation.
Second, the bootstrapping procedure implemented in PROCESS is thought to have higher power and more accuracy than alternatives such as the Sobel test.
A weakness, though, is that PROCESS does not generate regression residuals. These are often used to examine model assumptions such as linearity and homoscedasticity as discussed in Linear Regression in SPSS - A Simple Example.
Another weakness of PROCESS is that some very basic models are not possible at all in PROCESS. A simple example is parallel moderation as illustrated below.
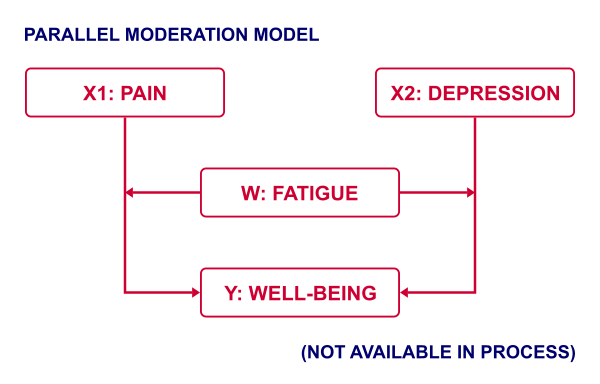
This can't be done because PROCESS is limited to a single X variable. Using just SPSS, estimating this model is a piece of cake. It's a tiny extension of the model discussed in SPSS Moderation Regression Tutorial.
A technical weakness is that PROCESS generates over 6,000 lines of syntax when pasted. The reason this happens is that PROCESS is built on 2 long deprecated SPSS techniques:
- the front end is an SPSS custom dialog (.spd) file. These have long been replaced by SPSS extension bundles (.spe files);
- the actual syntax is wrapped into a macro. SPSS macros have been deprecated in favor of Python ages ago.
I hope this will soon be fixed. There's really no need to bother SPSS users with 6,000 lines of source code.
Thanks for reading!
THIS TUTORIAL HAS 11 COMMENTS:
By Ruben Geert van den Berg on February 19th, 2024
Hi Asfaw, thanks for the compliment!
If you liked this article, you should definitely subscribe to our YouTube channel.
We're going to publish a lot of videos over the coming weeks and they're way better than the (older) written articles.
Thanks!
Ruben
SPSS tutorials