Cohen’s D – Effect Size for T-Test
Cohen’s D is the difference between 2 means
expressed in standard deviations.
- Cohen’s D - Formulas
- Cohen’s D and Power
- Cohen’s D & Point-Biserial Correlation
- Cohen’s D - Interpretation
- Cohen’s D for SPSS Users
Why Do We Need Cohen’s D?
Children from married and divorced parents completed some psychological tests: anxiety, depression and others. For comparing these 2 groups of children, their mean scores were compared using independent samples t-tests. The results are shown below.
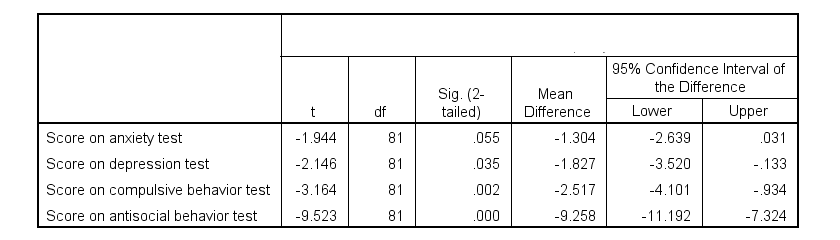
Some basic conclusions are that
- all mean differences are negative. So the second group -children from divorced parents- have higher means on all tests.
- Except for the anxiety test, all differences are statistically significant.
- The mean differences range from -1.3 points to -9.3 points.
However, what we really want to know is are these small, medium or large differences? This is hard to answer for 2 reasons:
- psychological test scores don't have any fixed unit of measurement such as meters, dollars or seconds.
- Statistical significance does not imply practical significance (or reversely). This is because p-values strongly depend on sample sizes.
A solution to both problems is using the standard deviation as a unit of measurement like we do when computing z-scores. And a mean difference expressed in standard deviations -Cohen’s D- is an interpretable effect size measure for t-tests.
Cohen’s D - Formulas
Cohen’s D is computed as
$$D = \frac{M_1 - M_2}{S_p}$$
where
- \(M_1\) and \(M_2\) denote the sample means for groups 1 and 2 and
- \(S_p\) denotes the pooled estimated population standard deviation.
But precisely what is the “pooled estimated population standard deviation”? Well, the independent-samples t-test assumes that the 2 groups we compare have the same population standard deviation. And we estimate it by “pooling” our 2 sample standard deviations with
$$S_p = \sqrt{\frac{(N_1 - 1) \cdot S_1^2 + (N_2 - 1) \cdot S_2^2}{N_1 + N_2 - 2}}$$
Fortunately, we rarely need this formula: SPSS, JASP and Excel readily compute a t-test with Cohen’s D for us.
Cohen’s D in JASP
Running the exact same t-tests in JASP and requesting “effect size” with confidence intervals results in the output shown below.
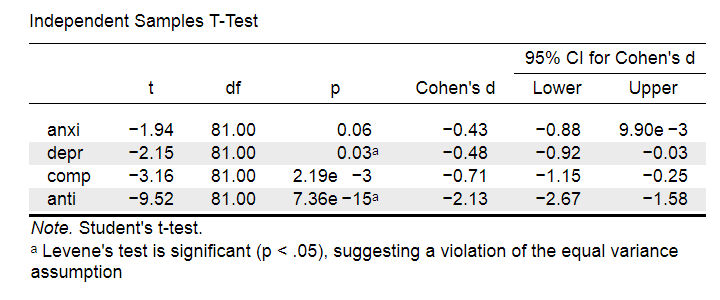
Note that Cohen’s D ranges from -0.43 through -2.13. Some minimal guidelines are that
- d = 0.20 indicates a small effect,
- d = 0.50 indicates a medium effect and
- d = 0.80 indicates a large effect.
And there we have it. Roughly speaking, the effects for
- the anxiety (d = -0.43) and depression tests (d = -0.48) are medium;
- the compulsive behavior test (d = -0.71) is fairly large;
- the antisocial behavior test (d = -2.13) is absolutely huge.
We'll go into the interpretation of Cohen’s D into much more detail later on. Let's first see how Cohen’s D relates to power and the point-biserial correlation, a different effect size measure for a t-test.
Cohen’s D and Power
Very interestingly, the power for a t-test can be computed directly from Cohen’s D. This requires specifying both sample sizes and α, usually 0.05. The illustration below -created with G*Power- shows how power increases with total sample size. It assumes that both samples are equally large.
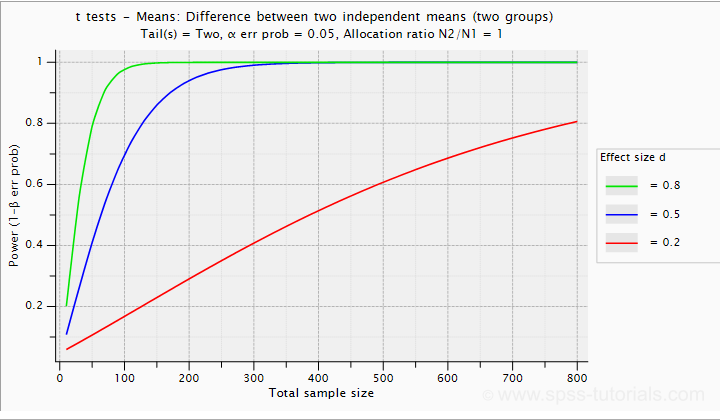
If we test at α = 0.05 and we want power (1 - β) = 0.8 then
- use 2 samples of n = 26 (total N = 52) if we expect d = 0.8 (large effect);
- use 2 samples of n = 64 (total N = 128) if we expect d = 0.5 (medium effect);
- use 2 samples of n = 394 (total N = 788) if we expect d = 0.2 (small effect);
Cohen’s D and Overlapping Distributions
The assumptions for an independent-samples t-test are
- independent observations;
- normality: the outcome variable must be normally distributed in each subpopulation;
- homogeneity: both subpopulations must have equal population standard deviations and -hence- variances.
If assumptions 2 and 3 are perfectly met, then Cohen’s D implies which percentage of the frequency distributions overlap. The example below shows how some male population overlaps with some 69% of some female population when Cohen’s D = 0.8, a large effect.
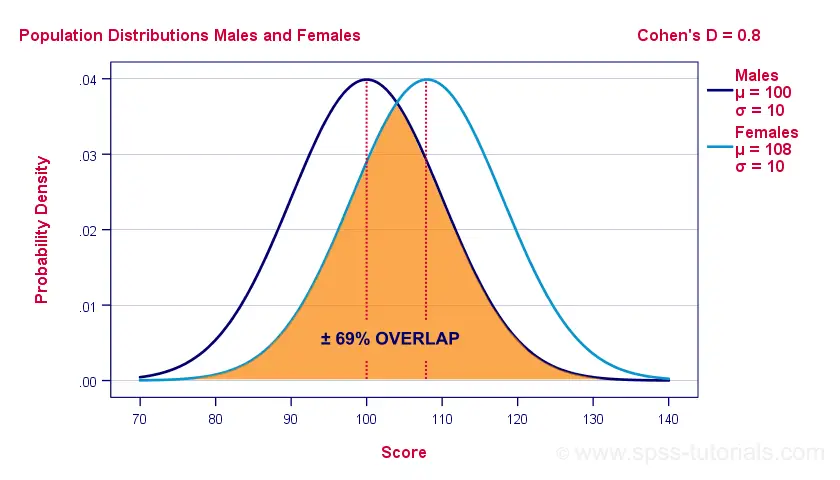
The percentage of overlap increases as Cohen’s D decreases. In this case, the distribution midpoints move towards each other. Some basic benchmarks are included in the interpretation table which we'll present in a minute.
Cohen’s D & Point-Biserial Correlation
An alternative effect size measure for the independent-samples t-test is \(R_{pb}\), the point-biserial correlation. This is simply a Pearson correlation between a quantitative and a dichotomous variable. It can be computed from Cohen’s D with
$$R_{pb} = \frac{D}{\sqrt{D^2 + 4}}$$
For our 3 benchmark values,
- Cohen’s d = 0.2 implies \(R_{pb}\) ± 0.100;
- Cohen’s d = 0.5 implies \(R_{pb}\) ± 0.243;
- Cohen’s d = 0.8 implies \(R_{pb}\) ± 0.371.
Alternatively, compute \(R_{pb}\) from the t-value and its degrees of freedom with
$$R_{pb} = \sqrt{\frac{t^2}{t^2 + df}}$$
Cohen’s D - Interpretation
The table below summarizes the rules of thumb regarding Cohen’s D that we discussed in the previous paragraphs.
| Cohen’s D | Interpretation | Rpb | % overlap | Recommended N |
|---|---|---|---|---|
| d = 0.2 | Small effect | ± 0.100 | ± 92% | 788 |
| d = 0.5 | Medium effect | ± 0.243 | ± 80% | 128 |
| d = 0.8 | Large effect | ± 0.371 | ± 69% | 52 |
Cohen’s D for SPSS Users
Cohen’s D is available in SPSS versions 27 and higher. It's obtained from
![]()
![]() as shown below.
as shown below.
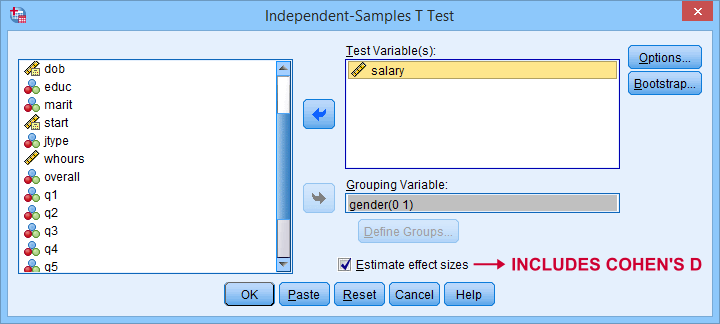
For more details on the output, please consult SPSS Independent Samples T-Test.
If you're using SPSS version 26 or lower, you can use Cohens-d.xlsx. This Excel sheet recomputes all output for one or many t-tests including Cohen’s D and its confidence interval from
- both sample sizes,
- both sample means and
- both sample standard deviations.
The input for our example data in divorced.sav and a tiny section of the resulting output is shown below.
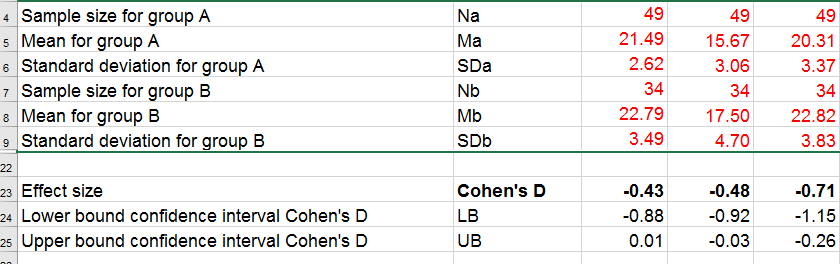
Note that the Excel tool doesn't require the raw data: a handful of descriptive statistics -possibly from a printed article- is sufficient.
SPSS users can easily create the required input from a simple MEANS command if it includes at least 2 variables. An example is
means anxi to anti by divorced
/cells count mean stddev.
Copy-pasting the SPSS output table as Excel preserves the (hidden) decimals of the results. These can be made visible in Excel and reduce rounding inaccuracies.
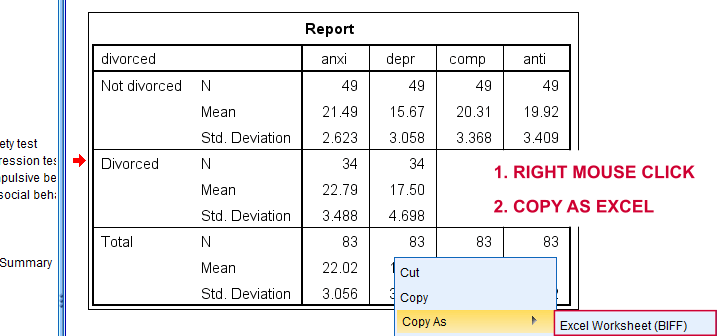
Final Notes
I think Cohen’s D is useful but I still prefer R2, the squared (Pearson) correlation between the independent and dependent variable. Note that this is perfectly valid for dichotomous variables and also serves as the fundament for dummy variable regression.
The reason I prefer R2 is that it's in line with other effect size measures: the independent-samples t-test is a special case of ANOVA. And if we run a t-test as an ANOVA, η2 (eta squared) = R2 or the proportion of variance accounted for by the independent variable. This raises the question:
why should we use a different effect size measure
if we compare 2 instead of 3+ subpopulations?
I think we shouldn't.
This line of reasoning also argues against reporting 1-tailed significance for t-tests: if we run a t-test as an ANOVA, the p-value is always the 2-tailed significance for the corresponding t-test. So why should you report a different measure for comparing 2 instead of 3+ means?
But anyway, that'll do for today. If you've any feedback -positive or negative- please drop us a comment below. And last but not least:
thanks for reading!
Confidence Intervals for Means in SPSS
- Assumptions for Confidence Intervals for Means
- Any Confidence Level - All Cases
- 95% Confidence Level - Separate Groups
- Any Confidence Level - Separate Groups
- Bonferroni Corrected Confidence Intervals
Confidence intervals for means are among the most essential statistics for reporting. Sadly, they're pretty well hidden in SPSS. This tutorial quickly walks you through the best (and worst) options for obtaining them. We'll use adolescents_clean.sav -partly shown below- for all examples.
Assumptions for Confidence Intervals for Means
Computing confidence intervals for means requires
- independent observations and
- normality: our variables must be normally distributed in the population represented by our sample.
1. A visual inspection of our data suggests that each case represents a distinct respondent so it seems safe to assume these are independent observations.
2. Second, the normality assumption is only required for small samples of N < 25 or so. For larger samples, the central limit theorem ensures that the sampling distributions for means, sums and proportions approximate normal distributions. In short,
our example data meet both assumptions.
Any Confidence Level - All Cases I
If we want to analyze all cases as a single group, our best option is the one sample t-test dialog.
The final output will include confidence intervals for the differences between our test value and our sample means. Now, if we use 0 as the test value, these differences will be exactly equal to our sample means.
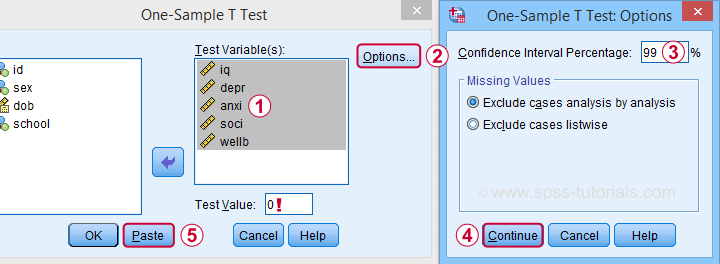
Clicking results in the syntax below. Let's run it.
T-TEST
/TESTVAL=0
/MISSING=ANALYSIS
/VARIABLES=iq depr anxi soci wellb
/CRITERIA=CI(.99).
Result
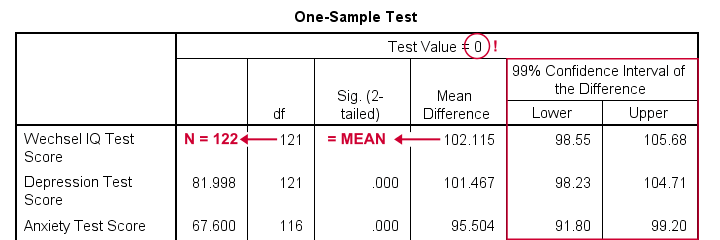
- as long as we use 0 as the test value, mean differences are equal to the actual means. This holds for their confidence intervals as well;
- the table indirectly includes the sample sizes: df = N - 1 and therefore N = df + 1.
Any Confidence Level - All Cases II
An alternative -but worse- option for obtaining these same confidence intervals is from
![]()
![]() We'll discuss these dialogs and their output in a minute under Any Confidence Level - Separate Groups II. They result in the syntax below.
We'll discuss these dialogs and their output in a minute under Any Confidence Level - Separate Groups II. They result in the syntax below.
EXAMINE VARIABLES=iq depr anxi soci wellb
/PLOT NONE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING PAIRWISE /*IMPORTANT!*/
/NOTOTAL.
*Minimal syntax - returns 95% CI's by default.
examine iq depr anxi soci wellb
/missing pairwise /*IMPORTANT!*/.
95% Confidence Level - Separate Groups
In many situations, analysts report statistics for separate groups such as male and female respondents. If these statistics include 95% confidence intervals for means, the way to go is the One-Way ANOVA dialog.
Now, sex is a dichotomous variable so we compare these 2 means with a t-test rather than an ANOVA -even though the significance levels are identical for these tests. However, the dialogs below result in a much nicer -and technically correct- descriptives table than the t-test dialogs.
 Descriptives includes 95% CI's for means but other confidence levels aren't available.
Descriptives includes 95% CI's for means but other confidence levels aren't available.
 Clicking results in the syntax below. Let's run it.
Clicking results in the syntax below. Let's run it.
ONEWAY iq depr anxi soci wellb BY sex
/STATISTICS DESCRIPTIVES .
Result
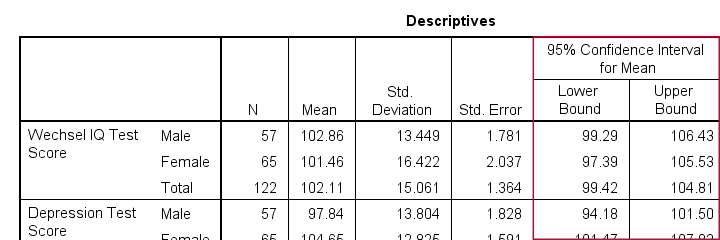
The resulting table has a nice layout that comes pretty close to the APA recommended format. It includes
- sample sizes;
- sample means;
- standard deviations and
- 95% CI's for means.
As mentioned, this method is restricted to 95% CI's. So let's look into 2 alternatives for other confidence levels.
Any Confidence Level - Separate Groups I
So how to obtain other confidence intervals for separate groups? The best option is adding a SPLIT FILE to the One Sample T-Test method. Since we discussed these dialogs and output under Any Confidence Level - All Cases I, we'll now just present the modified syntax.
sort cases by sex.
split file layered by sex.
*Obtain 95% CI's for means of iq to wellb.
T-TEST
/TESTVAL=0
/MISSING=ANALYSIS
/VARIABLES=iq depr anxi soci wellb
/CRITERIA=CI(.95).
*Switch off SPLIT FILE for succeeding output.
split file off.
Any Confidence Level - Separate Groups II
A last option we should mention is the Explore dialog as shown below.
We mostly discuss it for the sake of completeness because
SPSS’ Explore dialog is a real showcase of stupidity
and poor UX design.
Just a few of its shortcomings are that
- you can select “statistics” but not which statistics;
- if you do so, you always get a tsunami of statistics -the vast majority of which you don't want;
- what you probably do want are sample sizes but these are not available;
- the sample sizes that are actually used may be different than you think: in contrast to similar dialogs, Explore uses listwise exclusion of missing values by default;
- what you probably do want, is exclusion of missing values by analysis or variable. This is available but mislabeled “pairwise” exclusion.
- the Explore dialog generates an EXAMINE command so many users think these are 2 separate procedures.
For these reasons, I personally only use Explore for
These tests are under -the very last place you'd expect them.
But anyway, the steps shown below result in confidence intervals for means for males and females separately.
 Clicking generates the syntax below.
Clicking generates the syntax below.
EXAMINE VARIABLES=iq depr anxi soci wellb BY sex
/PLOT NONE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING PAIRWISE /*IMPORTANT!*/
/NOTOTAL.
*Minimal syntax - returns 95% CI's by default.
examine iq depr anxi soci wellb by sex
/missing pairwise /*IMPORTANT!*/
/nototal.
Result

Bonferroni Corrected Confidence Intervals
All examples in this tutorial used 5 outcome variables measured on the same sample of respondents. Now, a 95% confidence interval has a 5% chance of not enclosing the population parameter we're after. So for 5 such intervals, there's a (1 - 0.955 =) 0.226 probability that at least one of them is wrong.
Some analysts argue that this problem should be fixed by applying a Bonferroni correction. Some procedures in SPSS have this as an option as shown below.
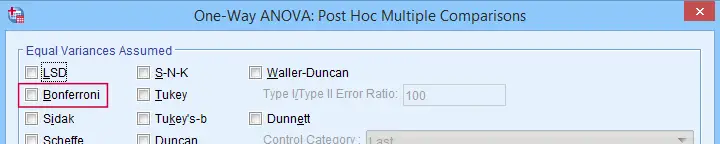
But what about basic confidence intervals? The easiest way is probably to adjust the confidence levels manually by
$$level_{adj} = 100\% - \frac{100\% - level_{unadj}}{N_i}$$
where \(N_i\) denotes the number of intervals calculated on the same sample. So some Bonferroni adjusted confidence levels are
- 95.00% if you calculate 1 (95%) confidence interval;
- 97.50% if you calculate 2 (95%) confidence intervals;
- 98.33% if you calculate 3 (95%) confidence intervals;
- 98.75% if you calculate 4 (95%) confidence intervals;
- 99.00% if you calculate 5 (95%) confidence intervals;
and so on.
Well, I think that should do. I can't think of anything else I could write on this topic. If you do, please throw us a comment below.
Thanks for reading!
What is a Dichotomous Variable?
A dichotomous variable is a variable that contains precisely two distinct values. Let's first take a look at some examples for illustrating this point. Next, we'll point out why distinguishing dichotomous from other variables makes it easier to analyze your data and choose the appropriate statistical test.
Examples
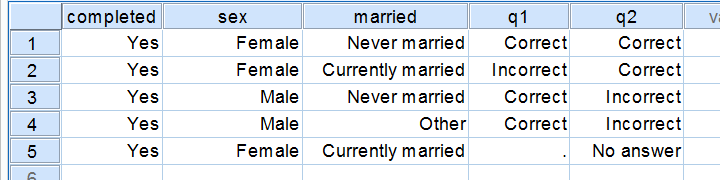
Regarding the data in the screenshot:
- completed is not a dichotomous variable. It contains only one distinct value and we therefore call it a constant rather than a variable.
- sex is a dichotomous variable as it contains precisely 2 distinct values.
- married is not a dichotomous variable: it contains 3 distinct values. It would be dichotomous if we just distinguished between currently married and currently unmarried.
- q1 is a dichotomous variable: since empty cells (missing values) are always excluded from analyses, we have two distinct values left.
- q2 is a dichotomous variable if we exclude the “no answer” category from analysis and not dichotomous otherwise.
Dichotomous Variables - What Makes them Special?
Dichotomous are the simplest possible variables. The point here is that -given the sample size- the frequency distribution of a dichotomous variable can be exactly described with a single number: if we've 100 observations on sex and 45% is male, then we know all there is to know about this variable.
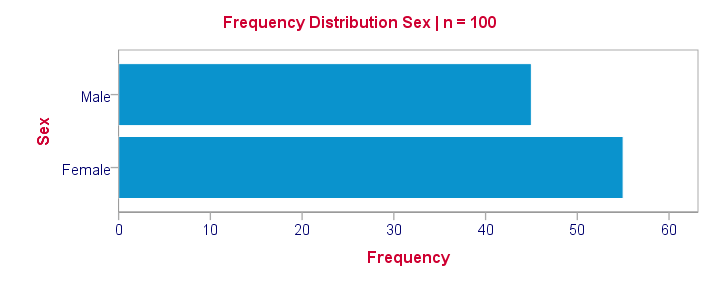
Note that this doesn't hold for other categorical variables: if we know that 45% of our sample (n = 100) has brown eyes, then we don't know the percentages of blue eyes, green eyes and so forth. That is, we can't describe the exact frequency distribution with one single number.
Something similar holds for metric variables: if we know the average age of our sample (n = 100) is precisely 25 years old, then we don't know the variance, skewness, kurtosis and so on needed for drawing a histogram.
Dichotomous Variables are both Categorical and Metric
Choosing the right data analysis techniques becomes much easier if we're aware of the measurement levels of the variables involved. The usual classification involves categorical (nominal, ordinal) and metric (interval, ratio) variables. Dichotomous variables, however, don't fit into this scheme because they're both categorical and metric.
This odd feature (which we'll illustrate in a minute) also justifies treating dichotomous variables as a separate measurement level.
Dichotomous Outcome Variables
Some research questions involve dichotomous dependent (outcome) variables. If so, we use proportions or percentages as descriptive statistics for summarizing such variables. For instance, people may or may consider buying a new car in 2017. We might want to know the percentage of people who do. This question is answered with either a binomial test or a z-test for one proportion.
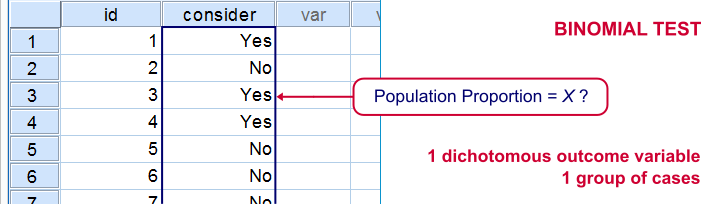
The aforementioned tests -and some others- are used exclusively for dichotomous dependent variables. They are among the most widely used (and simplest) stasticical tests around.
Dichotomous Input Variables
An example of a test using a dichotomous independent (input) variable is the independent samples t-test, illustrated below.
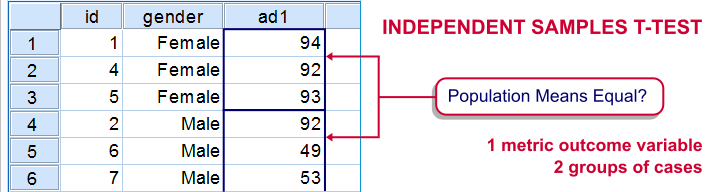
In this test, the dichotomous variable defines groups of cases and hence is used as a categorical variable. Strictly, the independent-samples t-test is redundant because it's equivalent to a one-way ANOVA. However, the independent variable holding only 2 distinct values greatly simplifies the calculations involved. This is why this test is treated separately from the more general ANOVA in most text books.
Those familiar with regression may know that the predictors (or independent variables) must be metric or dichotomous. In order to include a categorical predictor, it must be converted to a number of dichotomous variables, commonly referred to as dummy variables.
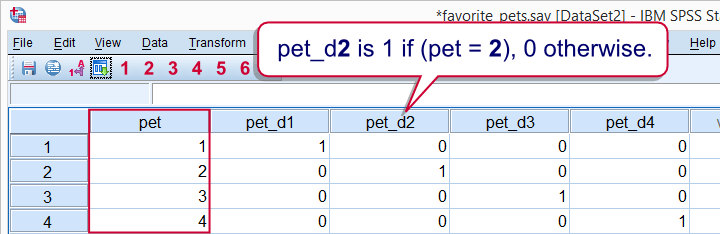
This illustrates that in regression, dichotomous variables are treated as metric rather than categorical variables.
Dichotomizing Variables
Last but not least, a distinction is sometimes made between naturally dichotomous variables and unnaturally dichotomous variables. A variable is naturally dichotomous if precisely 2 values occur in nature (sex, being married or being alive). If a variable holds precisely 2 values in your data but possibly more in the real world, it's unnaturally dichotomous.
Creating unnaturally dichotomous variables from non dichotomous variables is known as dichotomizing. The final screenshot illustrates a handy but little known trick for doing so in SPSS.
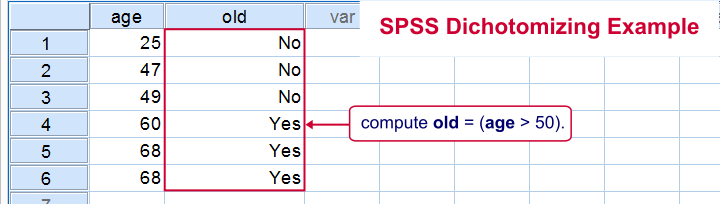
I hope you found this tutorial helpful. Thanks for reading!
Z-Scores – What and Why?
Quick Definition
Z-scores are scores that have mean = 0
and standard deviation = 1.
Z-scores are also known as standardized scores because they are scores that have been given a common standard. This standard is a mean of zero and a standard deviation of 1.
Contrary to what many people believe, z-scores are not necessarily normally distributed.
Z-Scores - Example
A group of 100 people took some IQ test. My score was 5. So is that good or bad? At this point, there's no way of telling because we don't know what people typically score on this test. However, if my score of 5 corresponds to a z-score of 0.91, you'll know it was pretty good: it's roughly a standard deviation higher than the average (which is always zero for z-scores).
What we see here is that standardizing scores facilitates the interpretation of a single test score. Let's see how that works.
Scores - Histogram
A quick peek at some of our 100 scores on our first IQ test shows a minimum of 1 and a maximum of 6. However, we'll gain much more insight into these scores by inspecting their histogram as shown below.
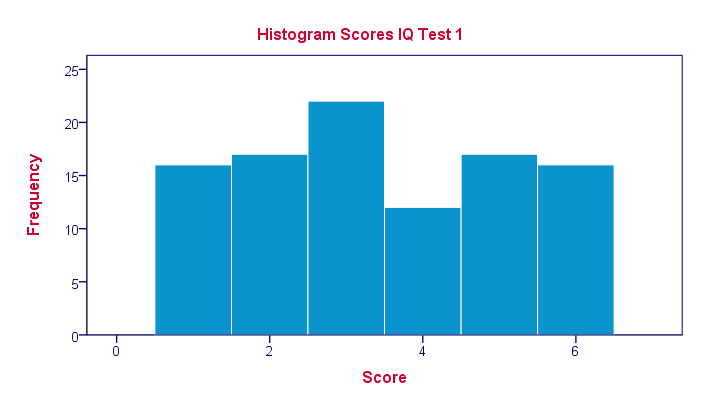
The histogram confirms that scores range from 1 through 6 and each of these scores occurs about equally frequently. This pattern is known as a uniform distribution and we typically see this when we roll a die a lot of times: numbers 1 through 6 are equally likely to come up. Note that these scores are clearly not normally distributed.
Z-Scores - Standardization
We suggested earlier on that giving scores a common standard of zero mean and unity standard deviation facilitates their interpretation. We can do just that by
- first subtracting the mean over all scores from each individual score and
- then dividing each remainder by the standard deviation over all scores.
These two steps are the same as the following formula:
$$Z_x = \frac{X_i - \overline{X}}{S_x}$$
As shown by the table below, our 100 scores have a mean of 3.45 and a standard deviation of 1.70.
 By entering these numbers into the formula, we see why a score of 5 corresponds to a z-score of 0.91:
By entering these numbers into the formula, we see why a score of 5 corresponds to a z-score of 0.91:
$$Z_x = \frac{5 - 3.45}{1.70} = 0.91$$
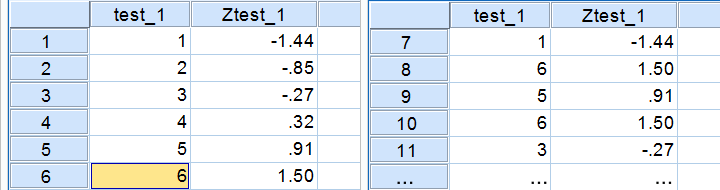
In a similar vein, the screenshot below shows the z-scores for all distinct values of our first IQ test added to the data.
Z-Scores - Histogram
In practice, we obviously have some software compute z-scores for us. We did so and ran a histogram on our z-scores, which is shown below.
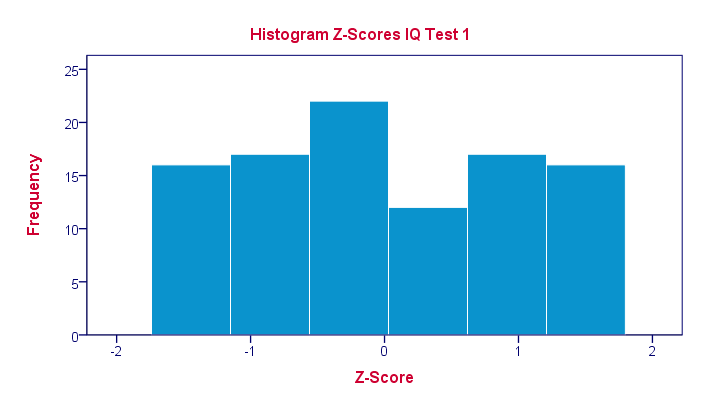 If you look closely, you'll notice that the z-scores indeed have a mean of zero and a standard deviation of 1. Other than that, however, z-scores follow the exact same distribution as original scores. That is, standardizing scores doesn't make their distribution more “normal” in any way.
If you look closely, you'll notice that the z-scores indeed have a mean of zero and a standard deviation of 1. Other than that, however, z-scores follow the exact same distribution as original scores. That is, standardizing scores doesn't make their distribution more “normal” in any way.
What's a Linear Transformation?
Z-scores are linearly transformed scores. What we mean by this, is that if we run a scatterplot of scores versus z-scores, all dots will be exactly on a straight line (hence, “linear”). The scatterplot below illustrates this. It contains 100 points but many end up right on top of each other.
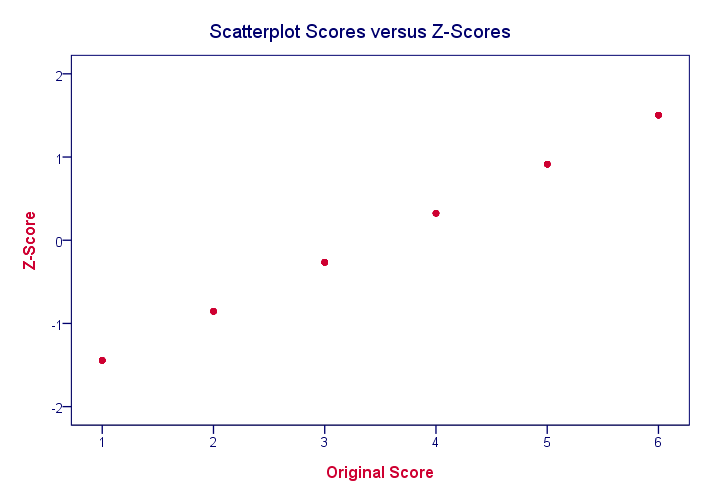
In a similar vein, if we had plotted scores versus squared scores, our line would have been curved; in contrast to standardizing, taking squares is a non linear transformation.
Z-Scores and the Normal Distribution
We saw earlier that standardizing scores doesn't change the shape of their distribution in any way; distribution don't become any more or less “normal”. So why do people relate z-scores to normal distributions?
The reason may be that many variables actually do follow normal distributions. Due to the central limit theorem, this holds especially for test statistics. If a normally distributed variable is standardized, it will follow a standard normal distribution.
This is a common procedure in statistics because values that (roughly) follow a standard normal distribution are easily interpretable. For instance, it's well known that some 2.5% of values are larger than two and some 68% of values are between -1 and 1.
The histogram below illustrates this: if a variable is roughly normally distributed, z-scores will roughly follow a standard normal distribution. For z-scores, it always holds (by definition) that a score of 1.5 means “1.5 standard deviations higher than average”. However, if a variable also follows a standard normal distribution, then we also know that 1.5 roughly corresponds to the 95th percentile.
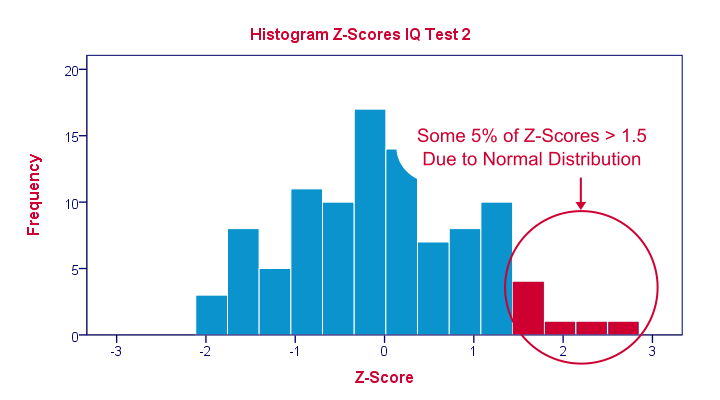
Z-Scores in SPSS
SPSS users can easily add z-scores to their data by using a DESCRIPTIVES command as in
descriptives test_1 test_2/save.
in which “save” means “save z-scores as new variables in my data”. For more details, see z-scores in SPSS.